又到了每年一度的解题环节了,我也是等了蛮久的,去年的这个时候都已经结束好久了,今年的春节太后面了,导致我以为都不会有了。
好吧,话不多说,我上一下自己的解题思路吧。纯小白
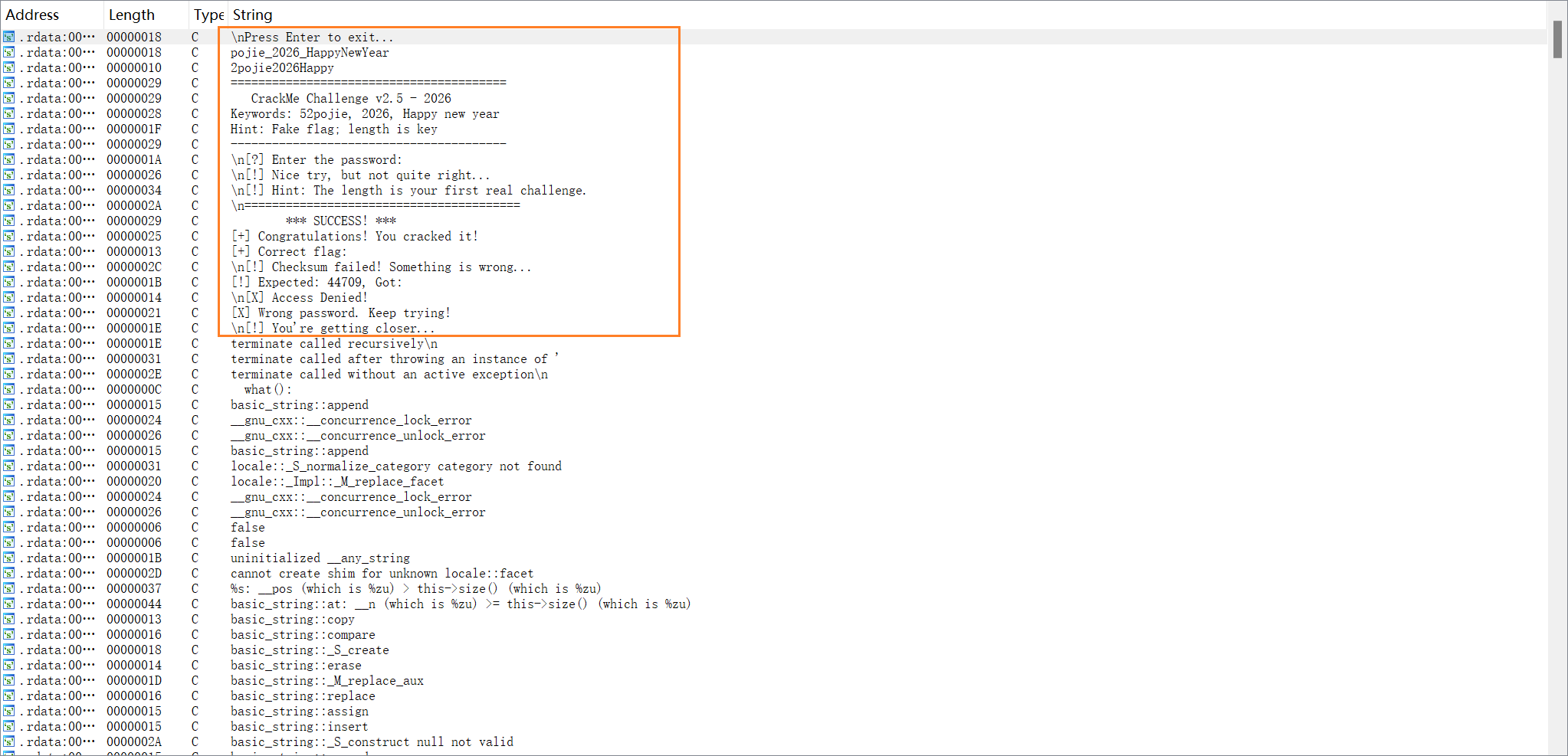
Windows 初级题(二) 用 Ida 打开后,shift + F12 可以看到如下关键词
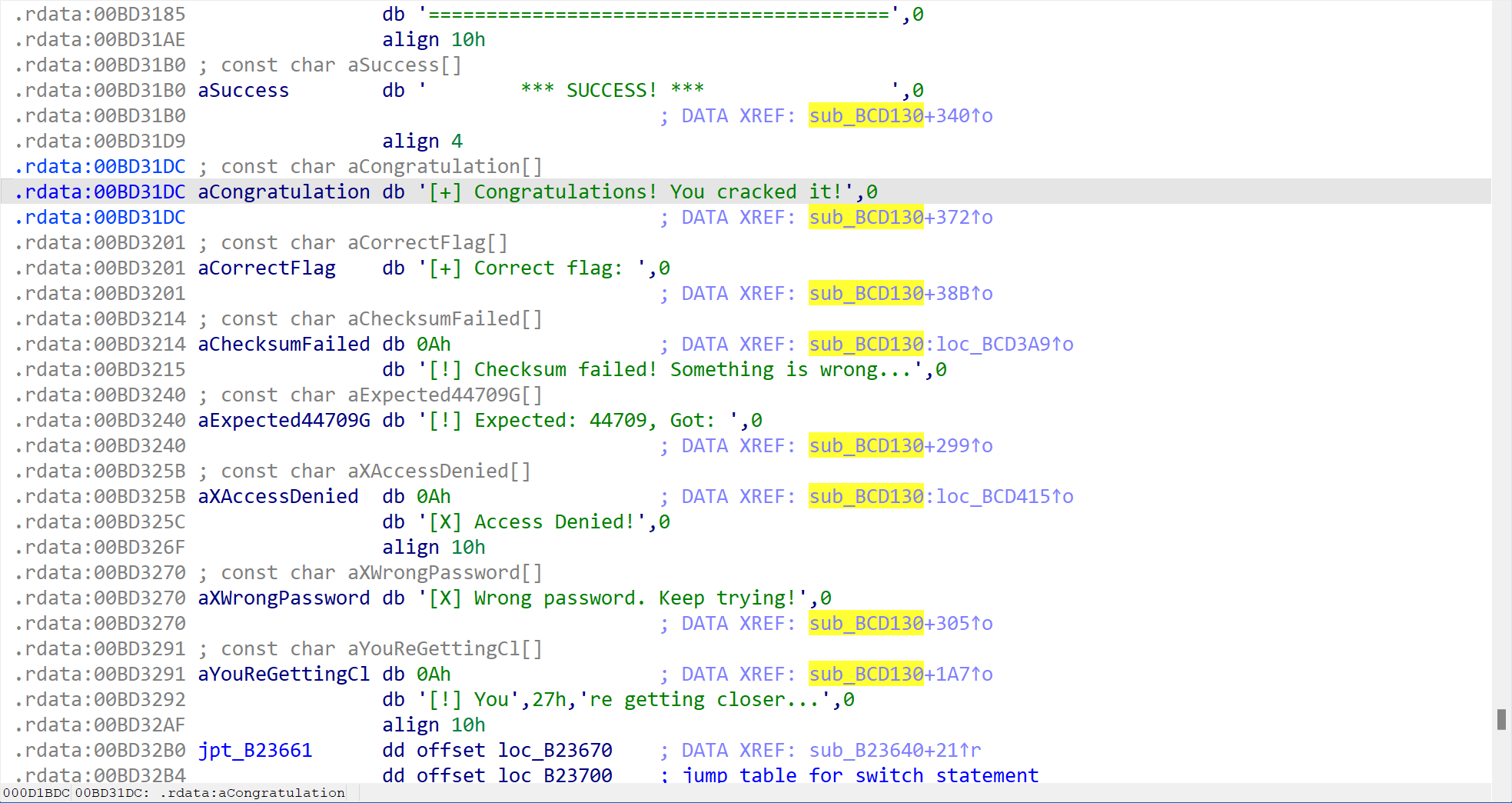
双击点进[+] Correct flag: ,可以看到一个关键函数sub_BCD130,这个函数就是验证函数了。
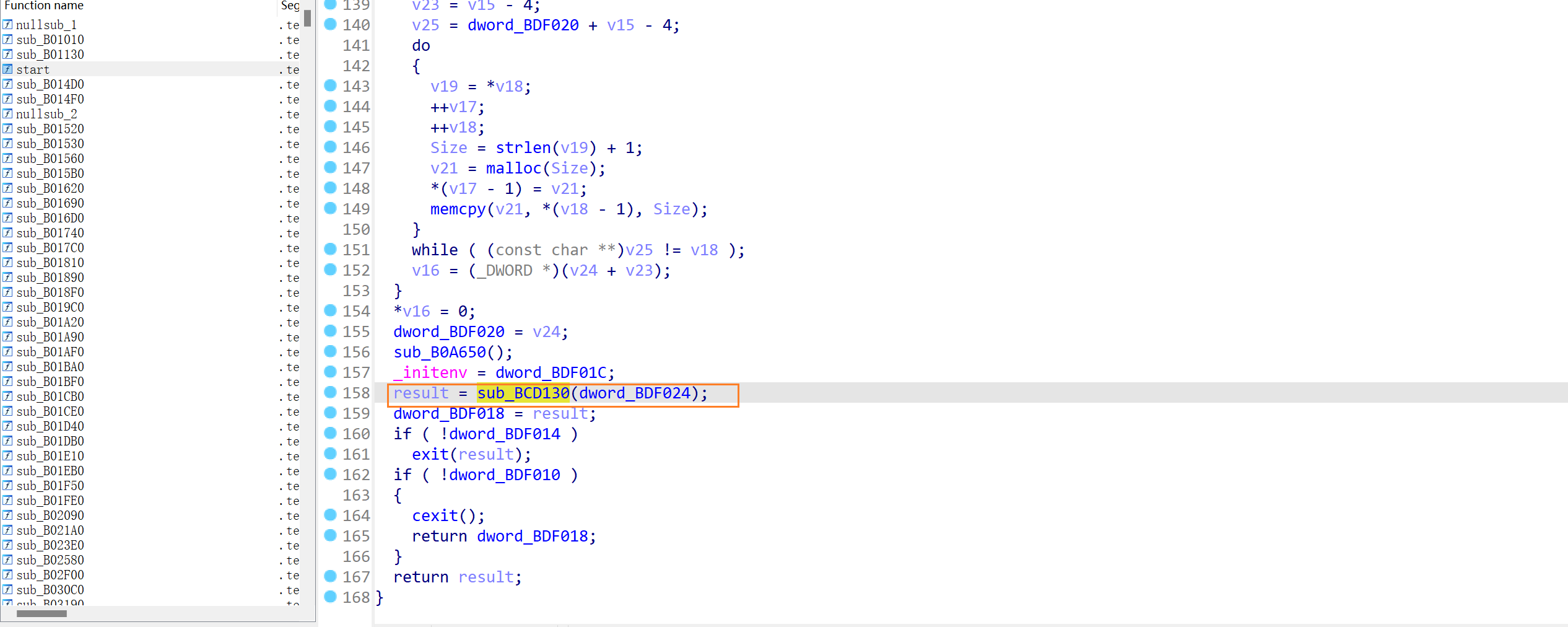
在左侧的窗口中找到start函数,按F5反编译,发现调用了验证函数。
1 result = sub_BCD130(dword_BDF024)
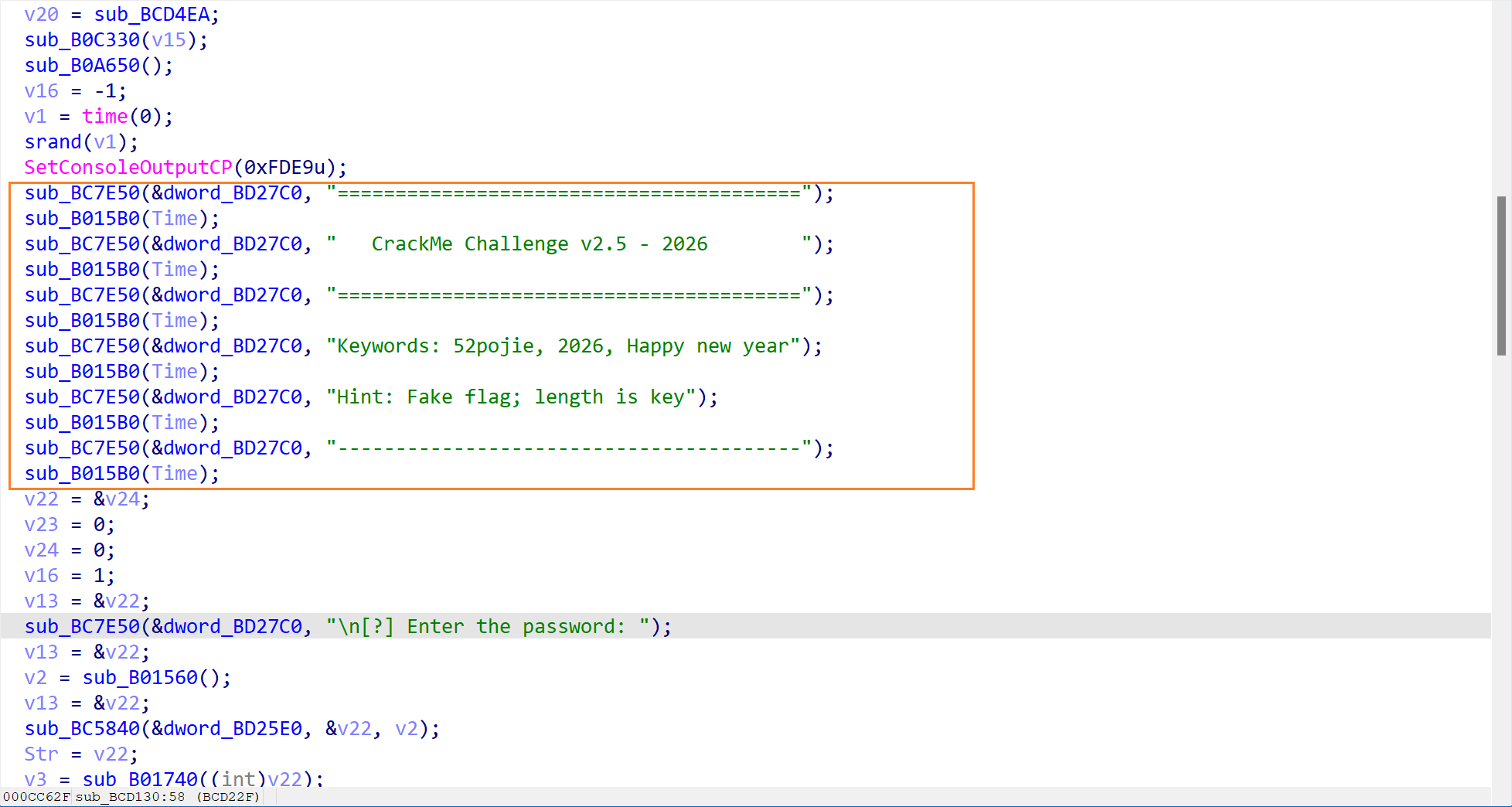
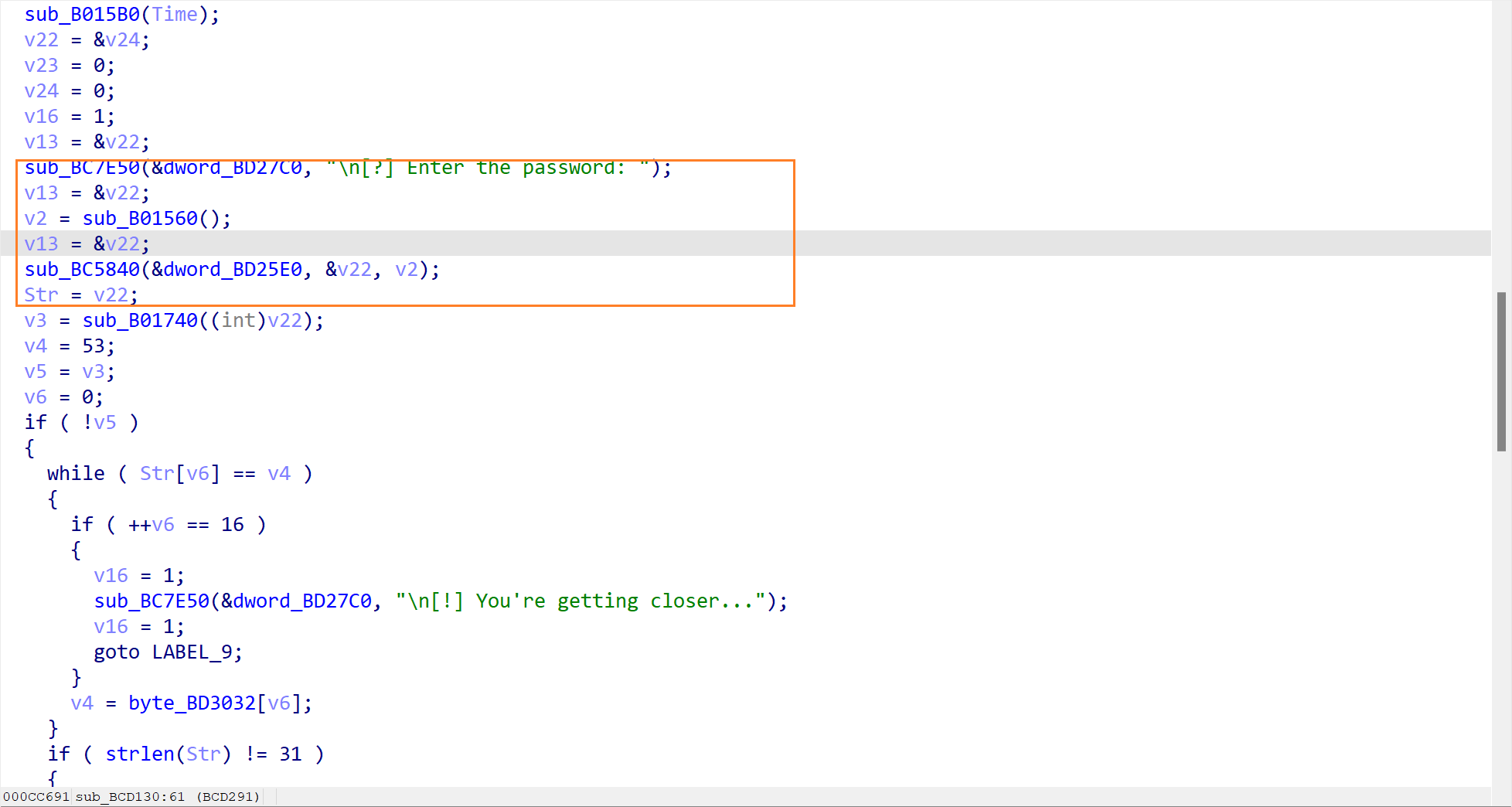
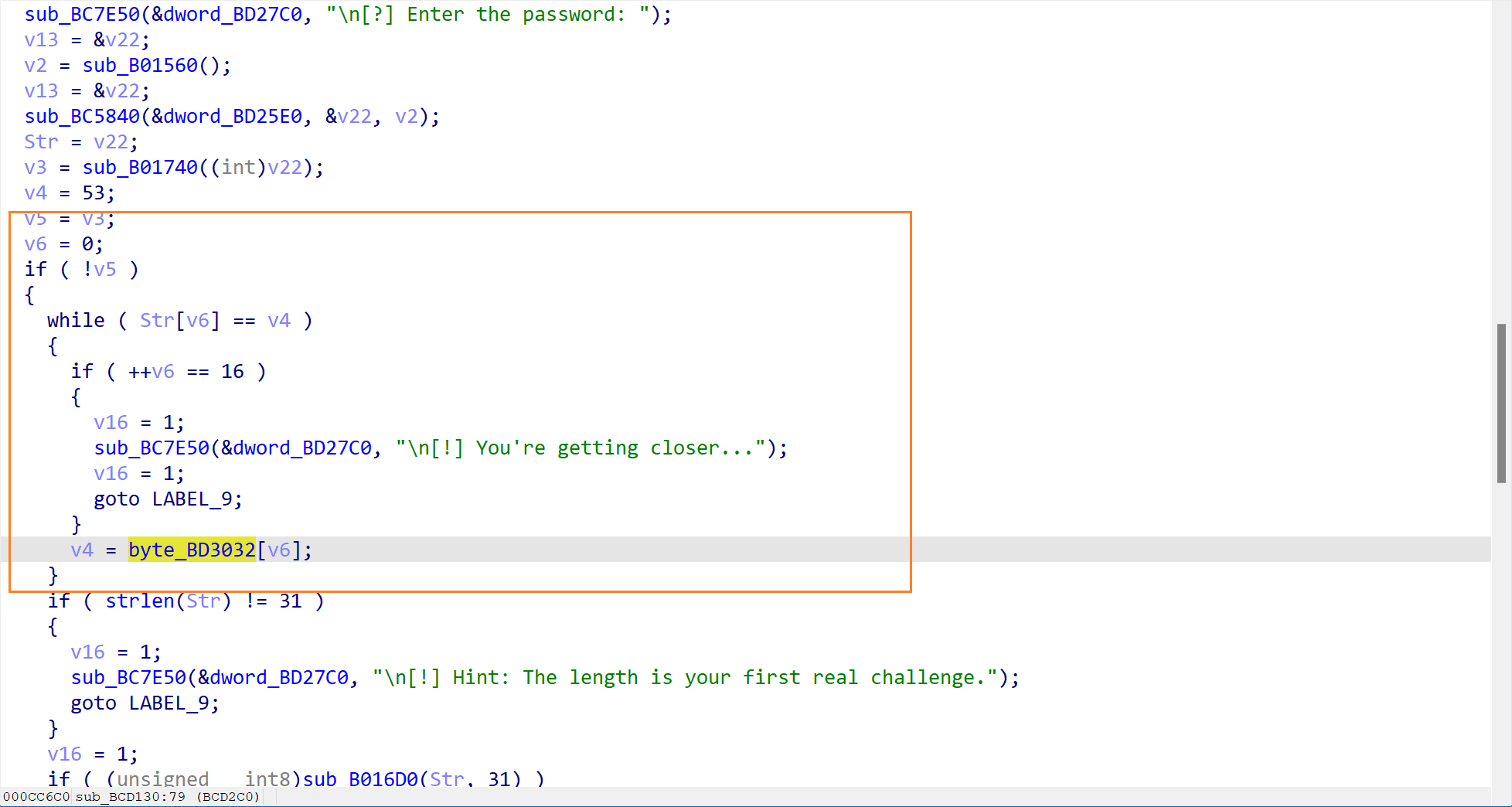
双击点进,就看到了这个验证函数的反编译代码了,分析一下这个函数的流程:
首先就打印了一个横幅,表示一些提示信息,告诉我们正确的 flag 长度是关键。
接着就让用户输入密码了,然后读取用户输入的内容
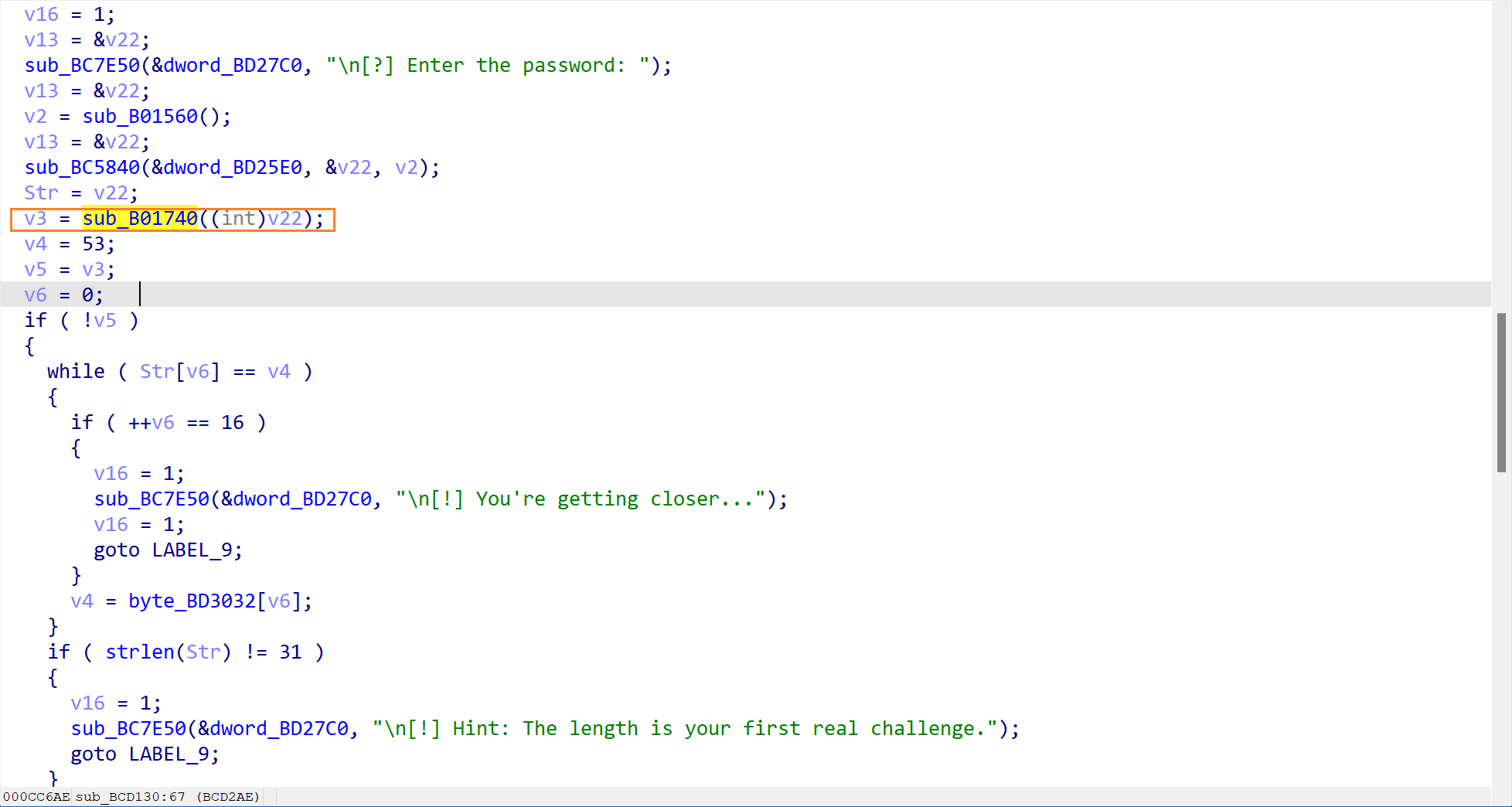
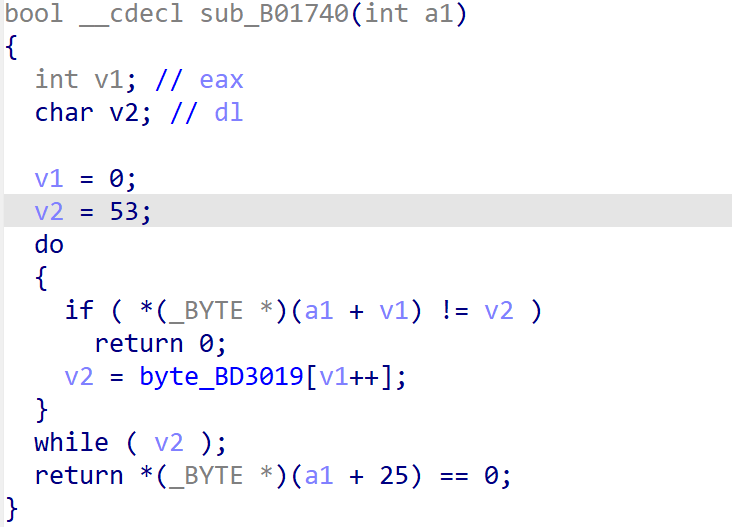
检查输入内容(sub_B01740) (第一个陷阱)
这一步检查了输入的内容,其内容为
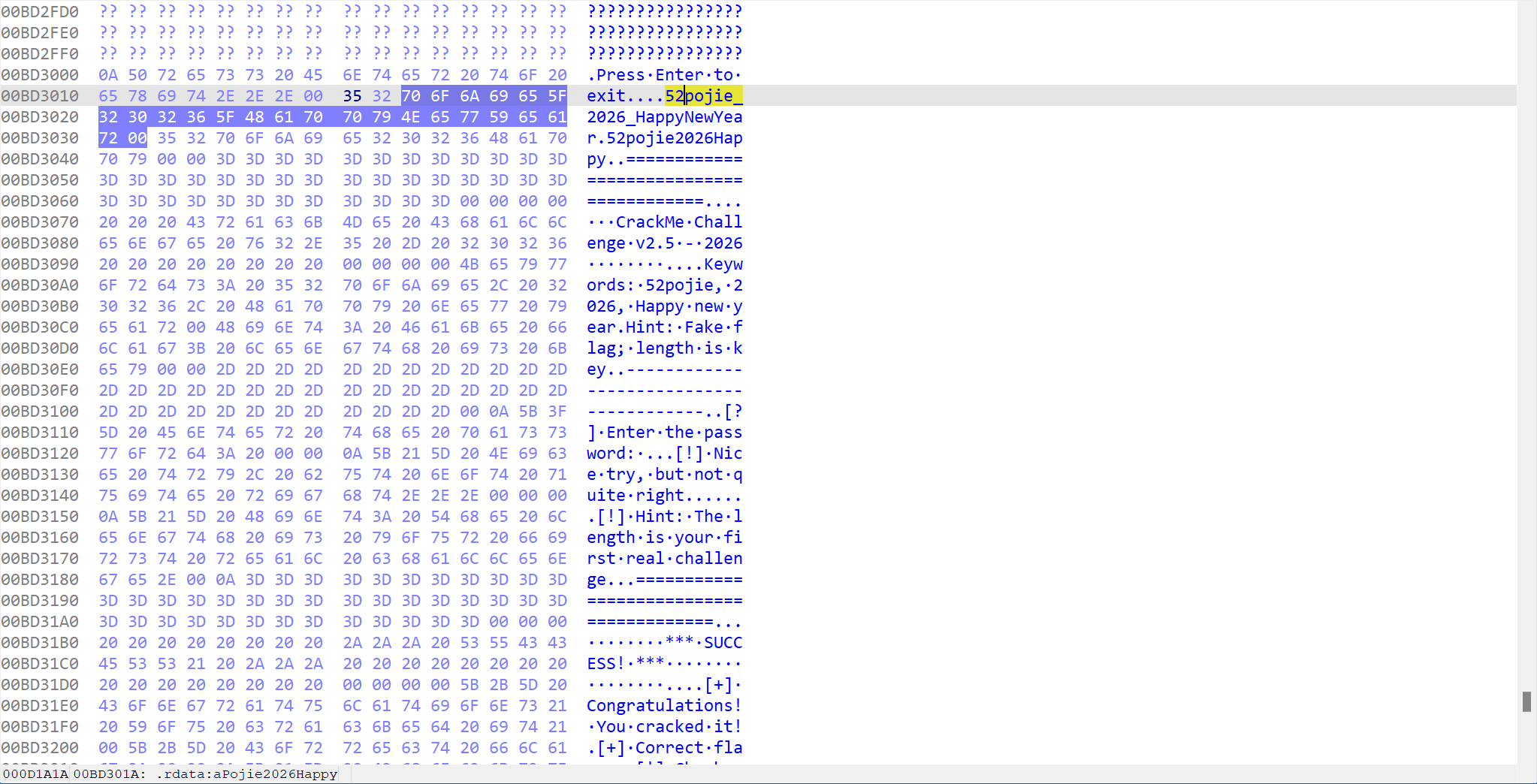
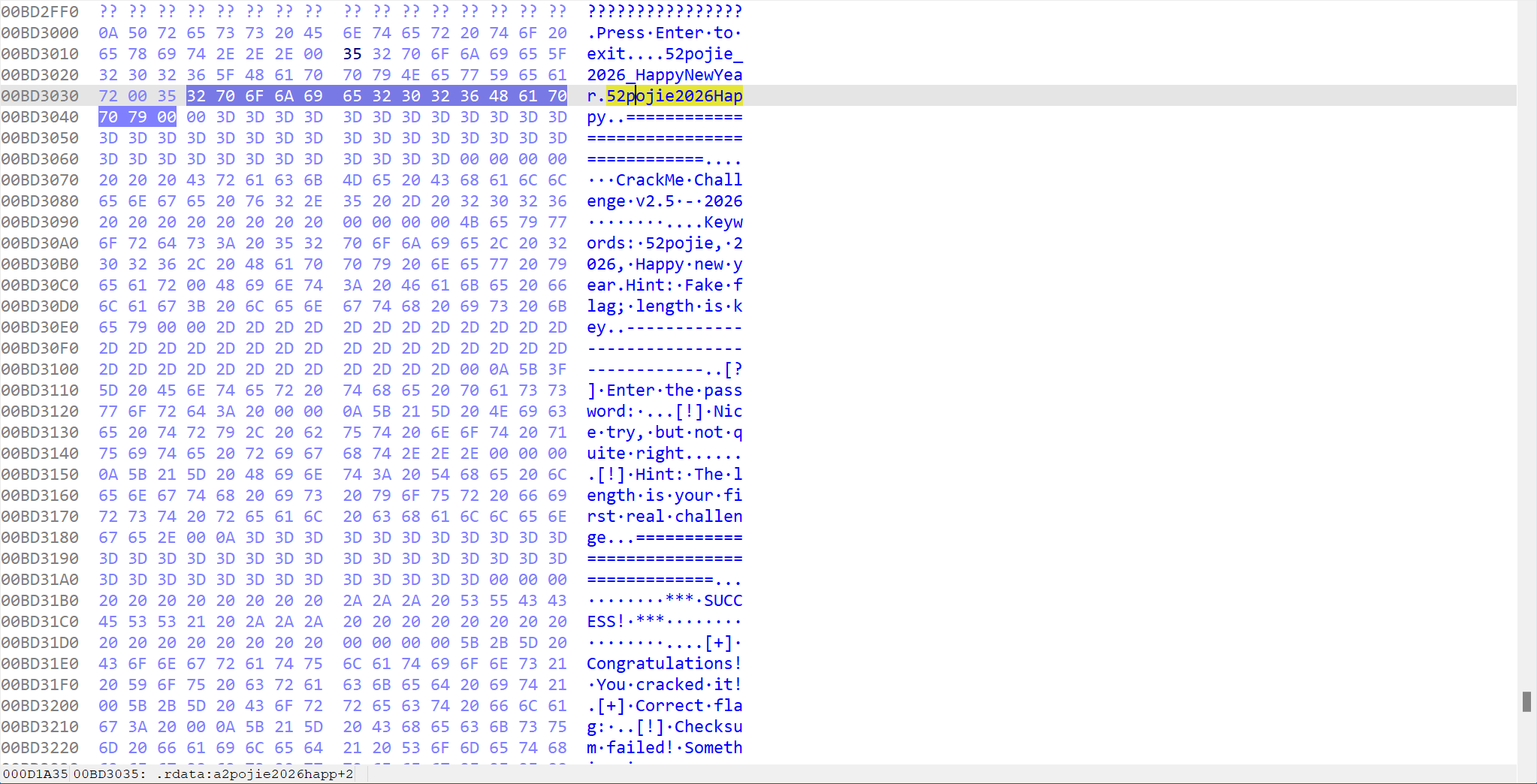
中间有一个v2 = byte_BD3019[v1++]。这里是一个关键点,它是一个数组,保存着一个假 Flag,也就是52pojie_2026_HappyNewYear,这是一个诱饵。通过 Hex view 可以看到这个诱饵。
函数是从53(ASCII ‘5’)开始的,然后逐字符读取byte_BD3019里的内容。
前 16 字符对比 (第二个陷阱)
这一步是对输入的前十六个字符进行对比,这里也有一个数组(byte_BD3032), 其内容为52pojie2026Happy. 如果此刻输入的内容前 16 为刚好匹配,就会进入 You're getting closer 的分支,提示我们输入的内容已经很接近了。
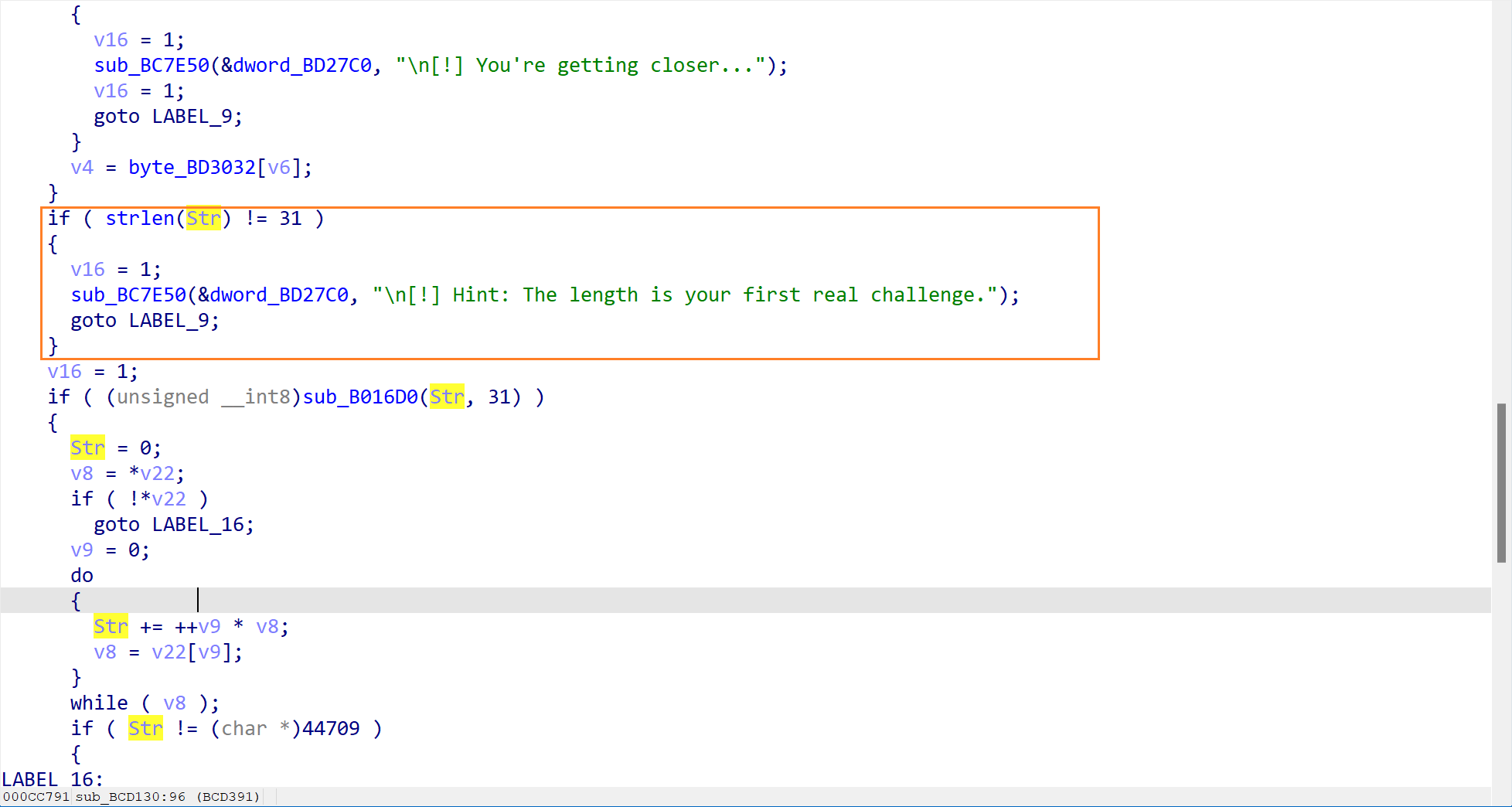
长度验证
通过前面两个陷阱,我们知道了两个线索,现在让我们继续分析下一部分的代码
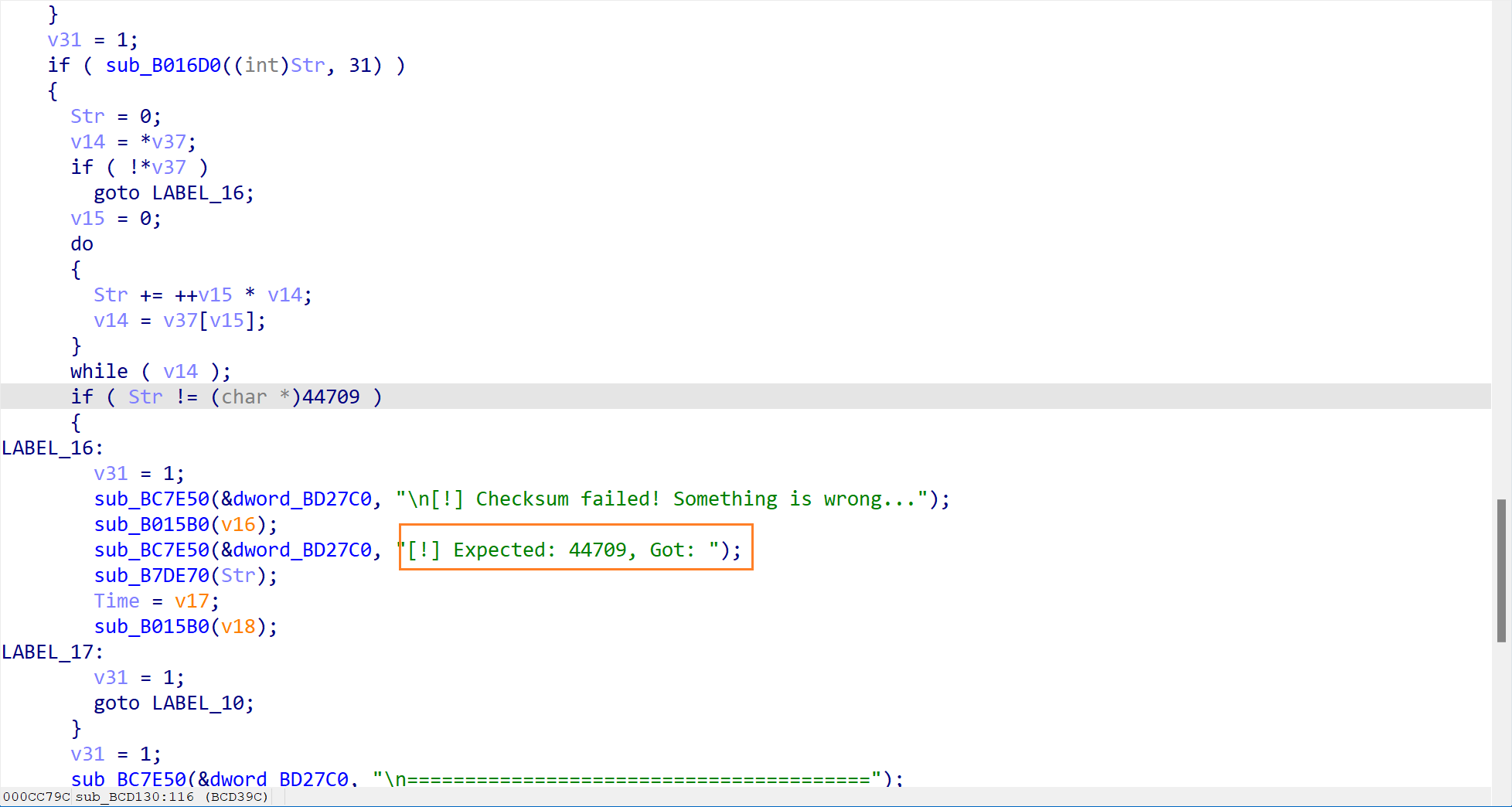
此处代码提示我们密码必须要求为 31 个字符。也就是说,正确的 flag 长度必须为 31 个字符。
XOR 缓冲区比对
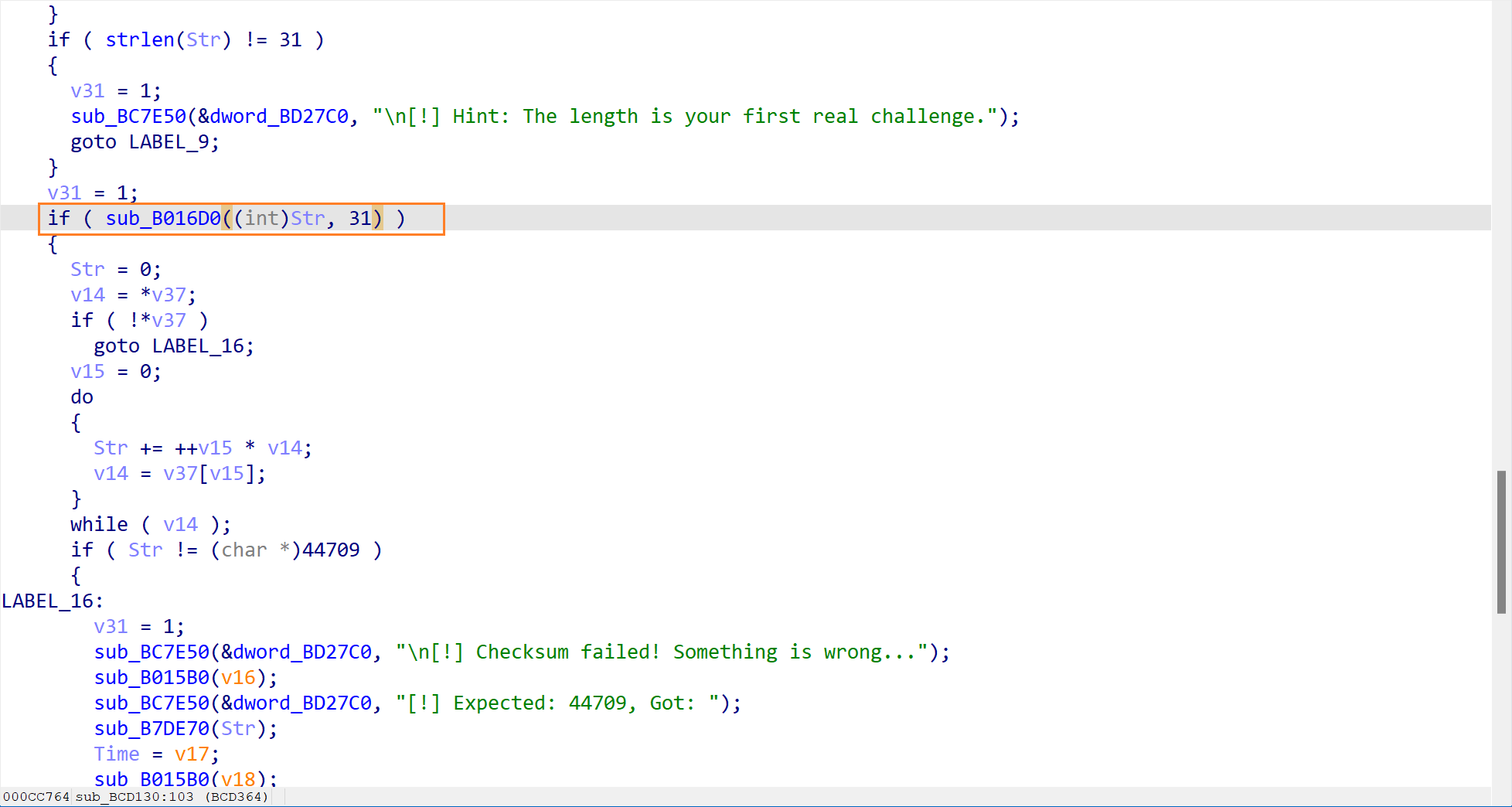
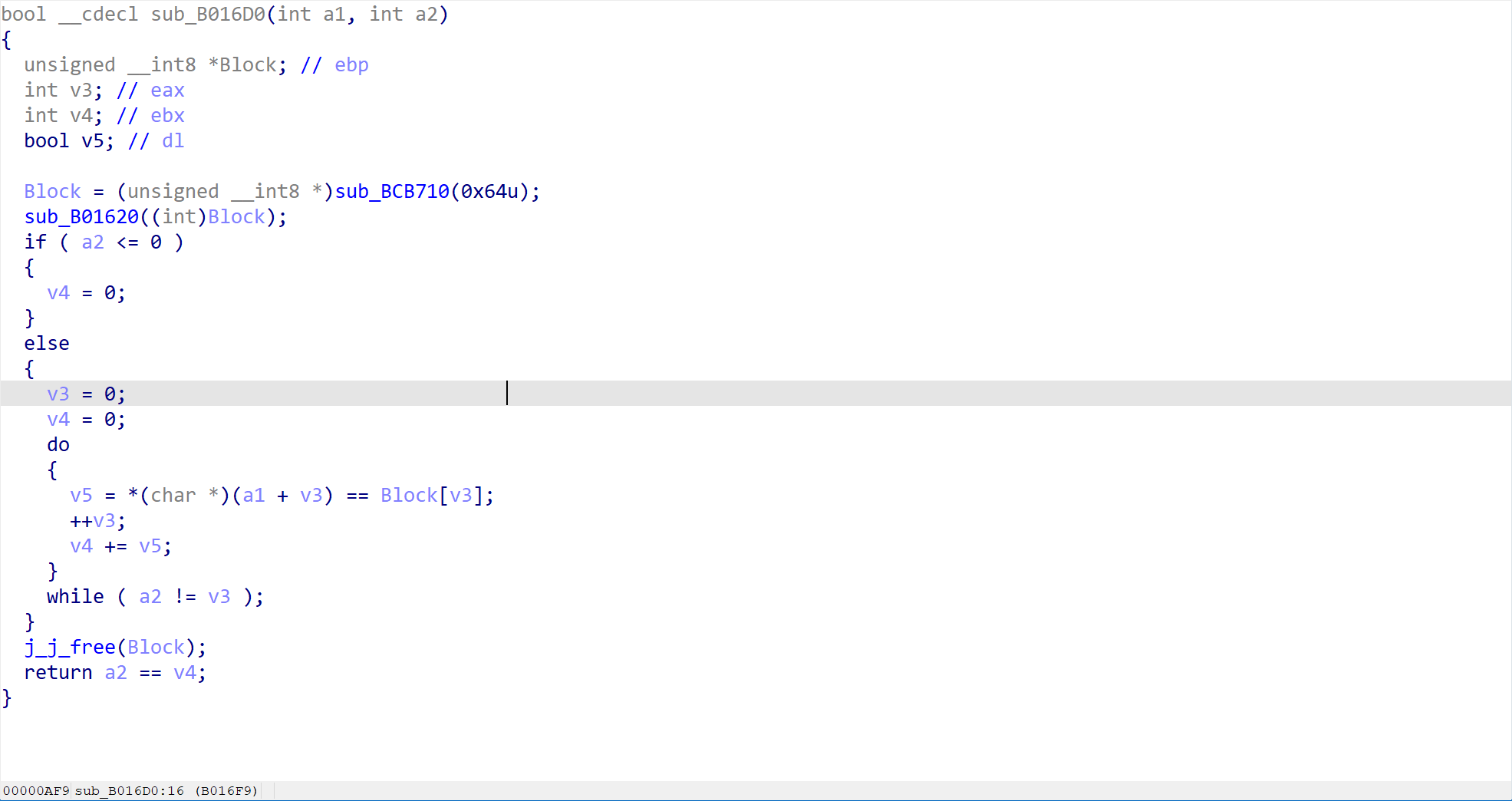
这是核心的验证部分了。程序调用了一个函数sub_B016D0来判断是否是正确的 flag
双击进入这个函数,查看具体的实现
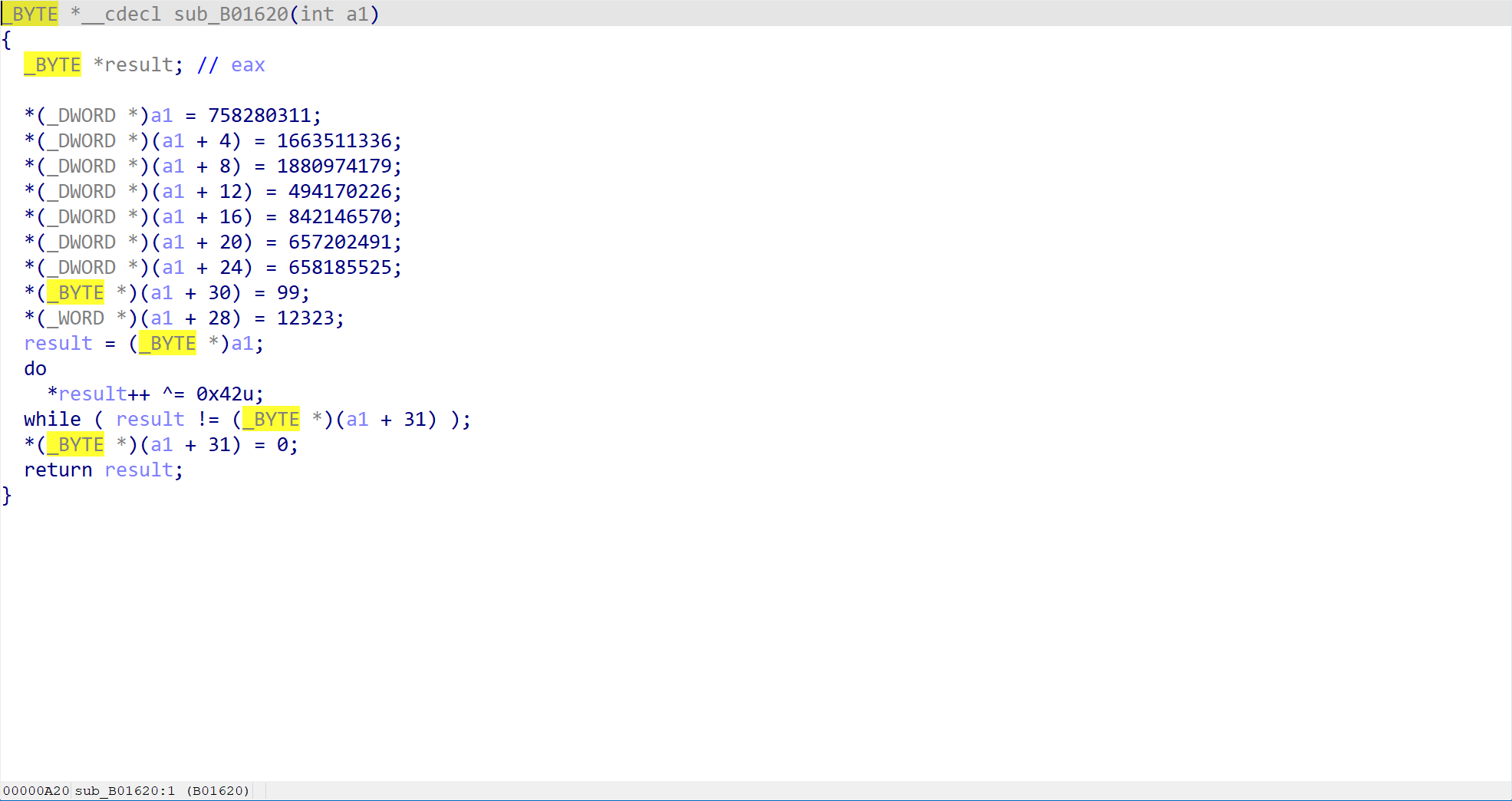
在这里有一个非常关键的函数,也就是sub_B01620。这一步直接就告诉了我们正确的答案。
通过这里的分析,可以知道每个字节进行了 XOR 0x42 的操作。交给 AI 来帮我们写一个简单的脚本来解密这个 XOR 缓冲区,得到正确的 flag。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import structbytearray (32 )'<I' , buf, 0 , 758280311 )'<I' , buf, 4 , 1663511336 )'<I' , buf, 8 , 1880974179 )'<I' , buf, 12 , 494170226 )'<I' , buf, 16 , 842146570 )'<I' , buf, 20 , 657202491 )'<I' , buf, 24 , 658185525 )'<H' , buf, 28 , 12323 )30 ] = 99 for i in range (31 ):0x42 31 ].decode('ascii' )print (f"Password: {password} " )print (f"Length: {len (password)} " )sum ((i + 1 ) * c for i, c in enumerate (password.encode()))print (f"Checksum: {checksum} (expected: 44709)" )
输出:
1 2 3 Password : 52 pojie!!!_2026_Happy_new_year!Length : 31 Checksum : 44709 (expected: 44709 )
输出的结果和我们前面知道的线索完全匹配,长度为 31,前 16 字符也不完全匹配,校验和也正确。
哦对了,忘记说怎么知道这个 checksum 了。
Checksum 验证
很简单,它直接写死了哈哈
至于计算方法也很简单
1 2 checksum = Σ (i × password[i-1] ) for i = 1 , 2 , ..., len1 ×p [0] + 2 ×p [1] + 3 ×p [2] + ... + 31 ×p [30]
最终验证
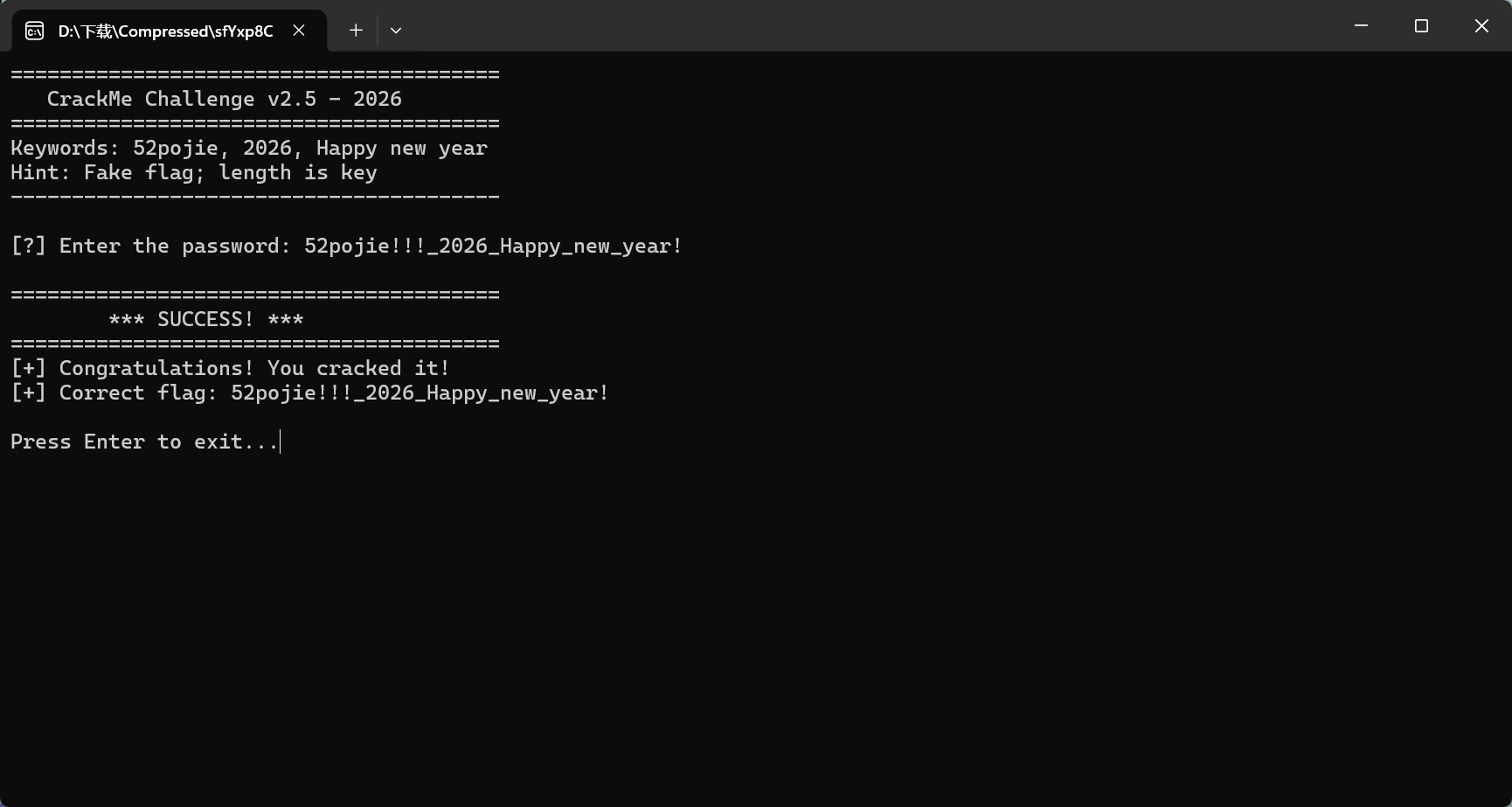
从上面的分析结果,我们知道了正确的 flag 是52pojie!!!_2026_Happy_new_year!,我们可以直接输入这个 flag 来验证一下。
至此,Windows 初级(二)就算是完全的解出来了。
Android 初级题(一) 简单的 Android 初级题,对于这个,咱有两个解法,一是好好的完成游戏然后 flag 就会跳出来了。二是直接反编译这个 APK,找到关键函数,分析一下就知道了。
咱们这里的选择是第二种,反编译分析。
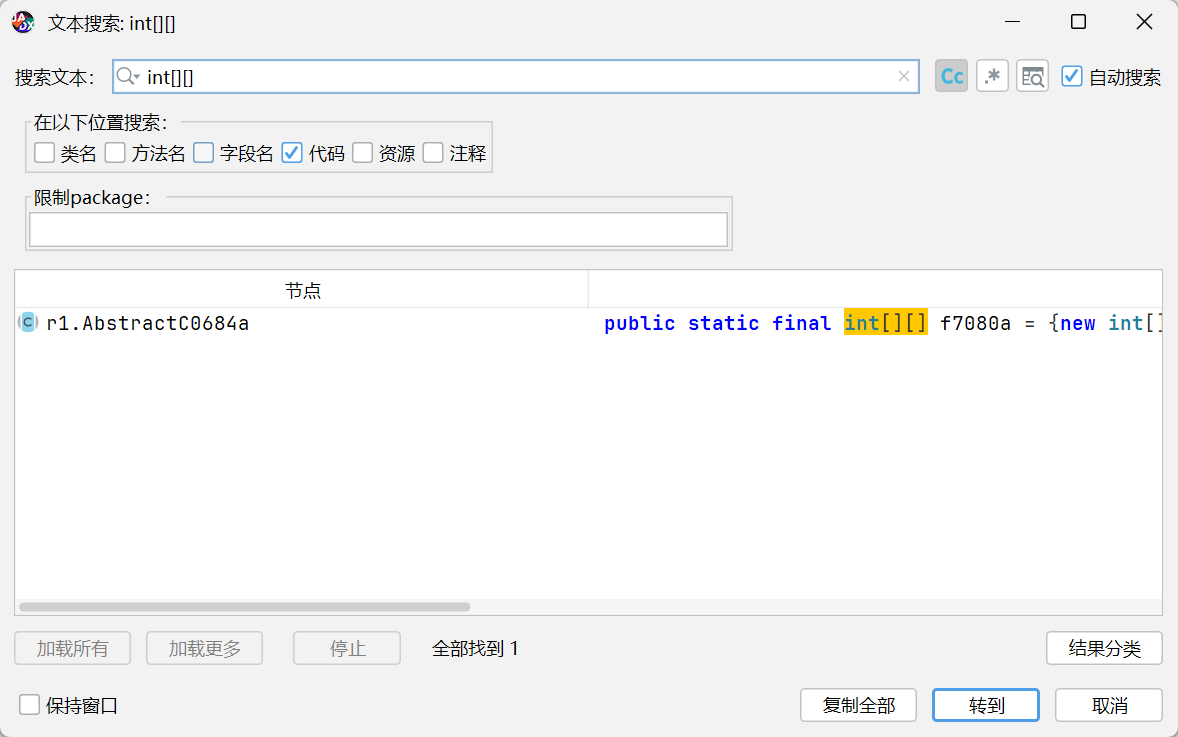
先用jadx打开这个 APK,搜索 int[][], 找到一个关键数组。这个数据很有可能就是加密后的数据,后面的解密也证实了确实是加密后的重要 flag 数据。另外按照经验,通常会用 XOR 来加密,所以咱们现在来找一下是谁调用了这个关键的数组
既然找到了这个关键数组,根据经验,52 的春节题目一般的都是 XOR 加密的,所以现在来找一下密钥在哪里。
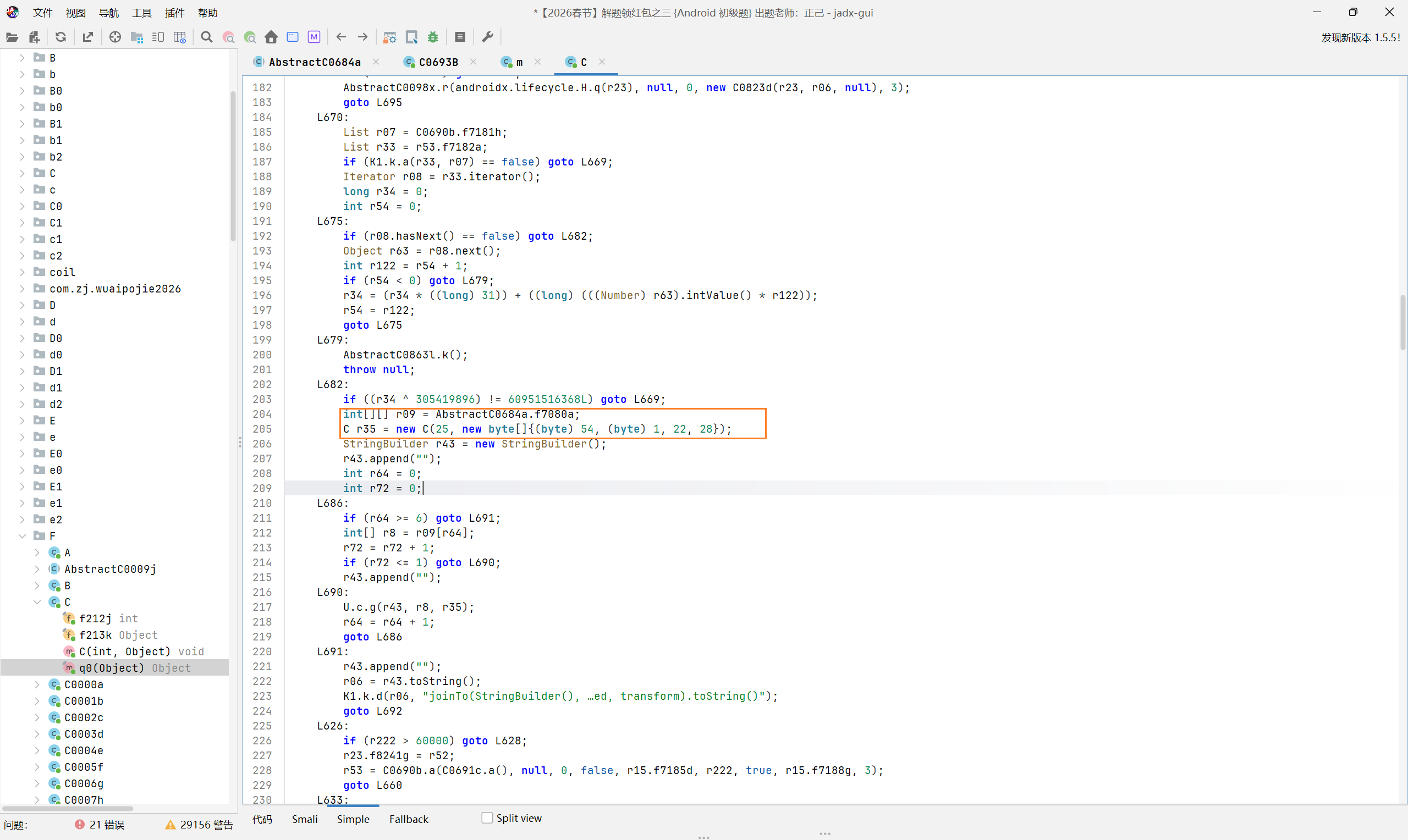
定位到 F.C.q0 方法,并且在下方看到了一个可疑的数据,假设这个 bytes 数据就是密钥,接下来找一下解密方法在哪里
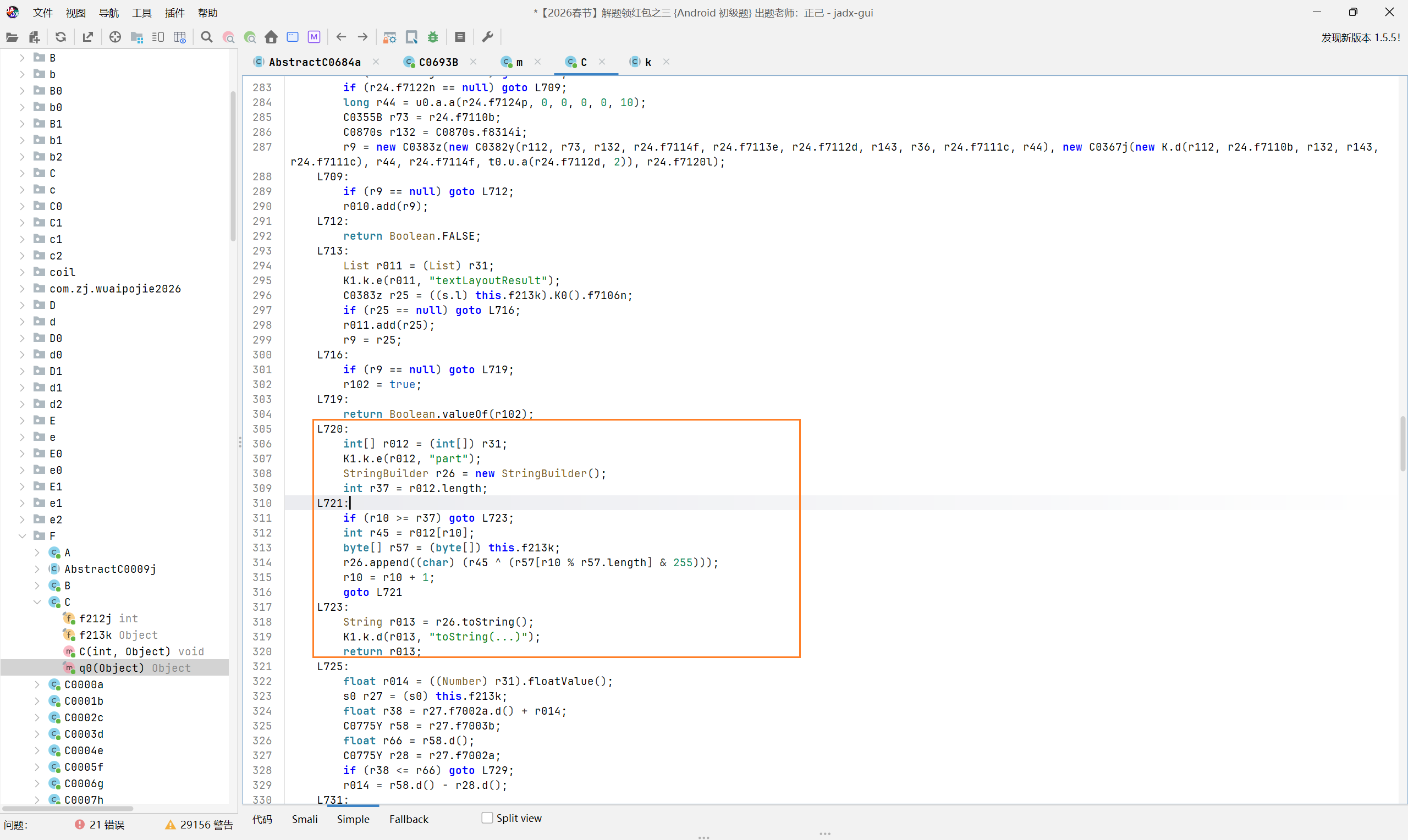
已知在传入的时候定义了 25,在代码中往上面翻一番,找到 case25 的分支,发现了这个解密
好了,现在知道了加密数据和密钥了,接下来就可以写一个简单的脚本来解密了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 key = [0x36 , 0x01 , 0x16 , 0x1C ]80 , 109 , 119 , 123 , 77 ],97 , 116 , 34 , 45 , 105 ],102 , 49 , 124 , 45 , 5 , 94 ],4 , 49 , 36 , 42 , 105 ],101 , 113 , 100 , 45 , 88 , 102 , 73 ],112 , 50 , 101 , 104 , 7 , 119 , 34 , 112 , 75 ]'' for part in data:for i, val in enumerate (part):chr (val ^ key[i % len (key)])print (flag)
输出:
1 flag {Wu41_P0j13_2026_Spr1ng_F3st1v4l}
或者咱们静态分析,直接用 Frida 来 hook 这个解密函数,直接把解密后的结果打印出来也是可以的。这里就不赘述了。
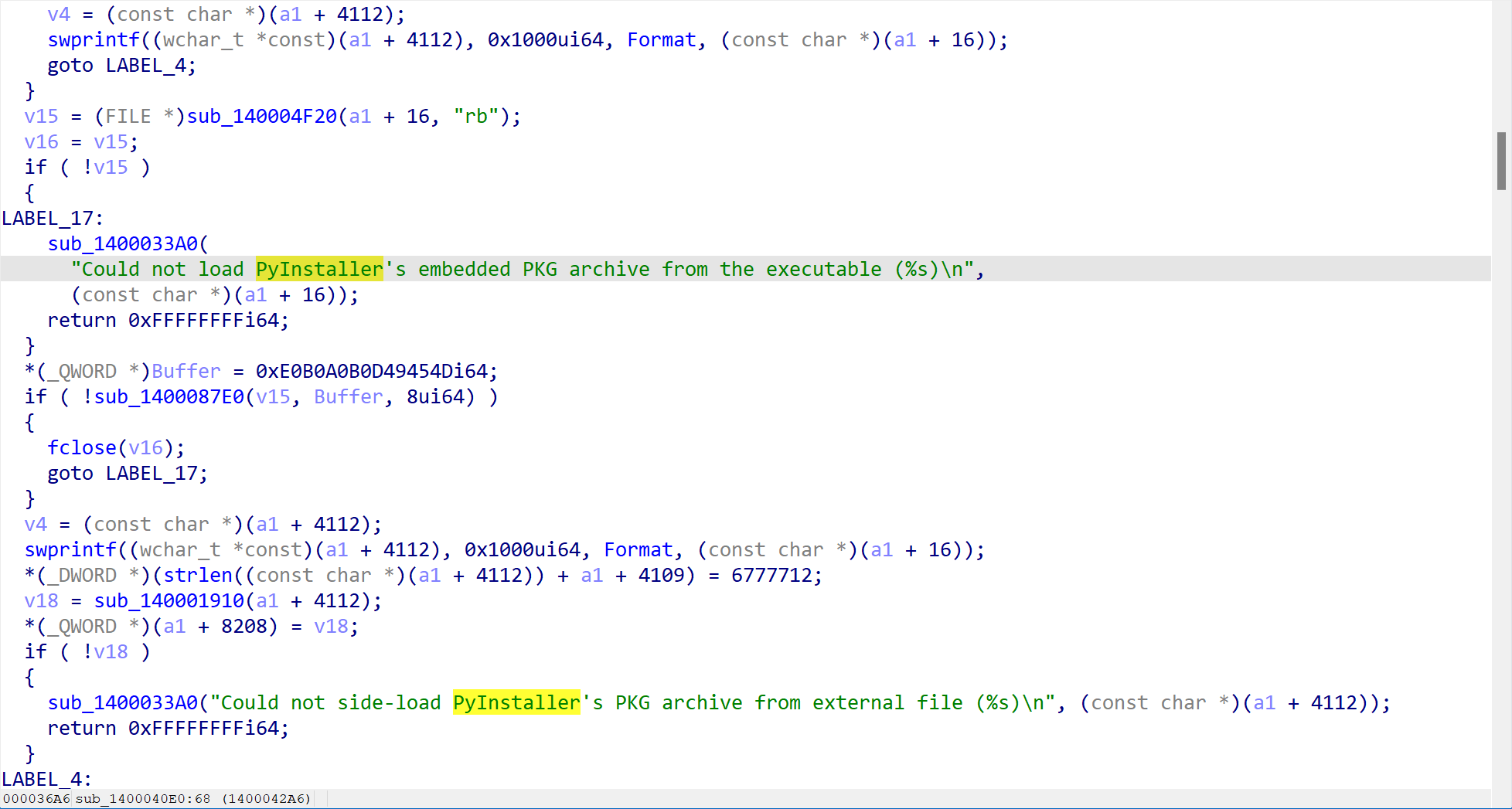
Windows 初级题(一) 先用Ida打开随便看一看,发现有PyInstaller特征,故此说明这是一个python程序被打包成了exe,知道这个就好办了。
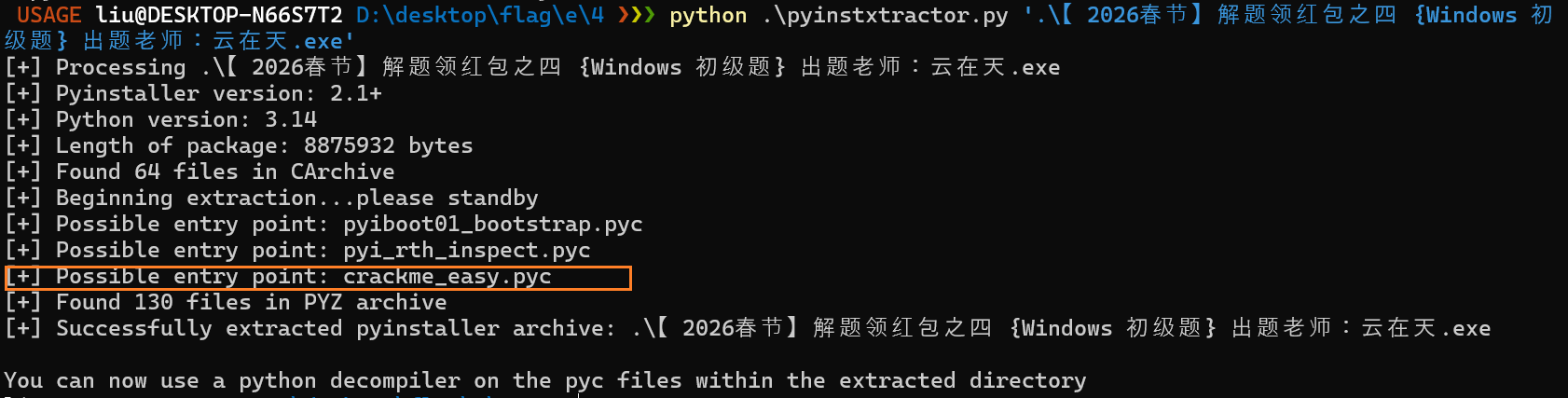
用pyinstxtractor 来解压这个exe,得到一个crakeme_easy.pyc的文件
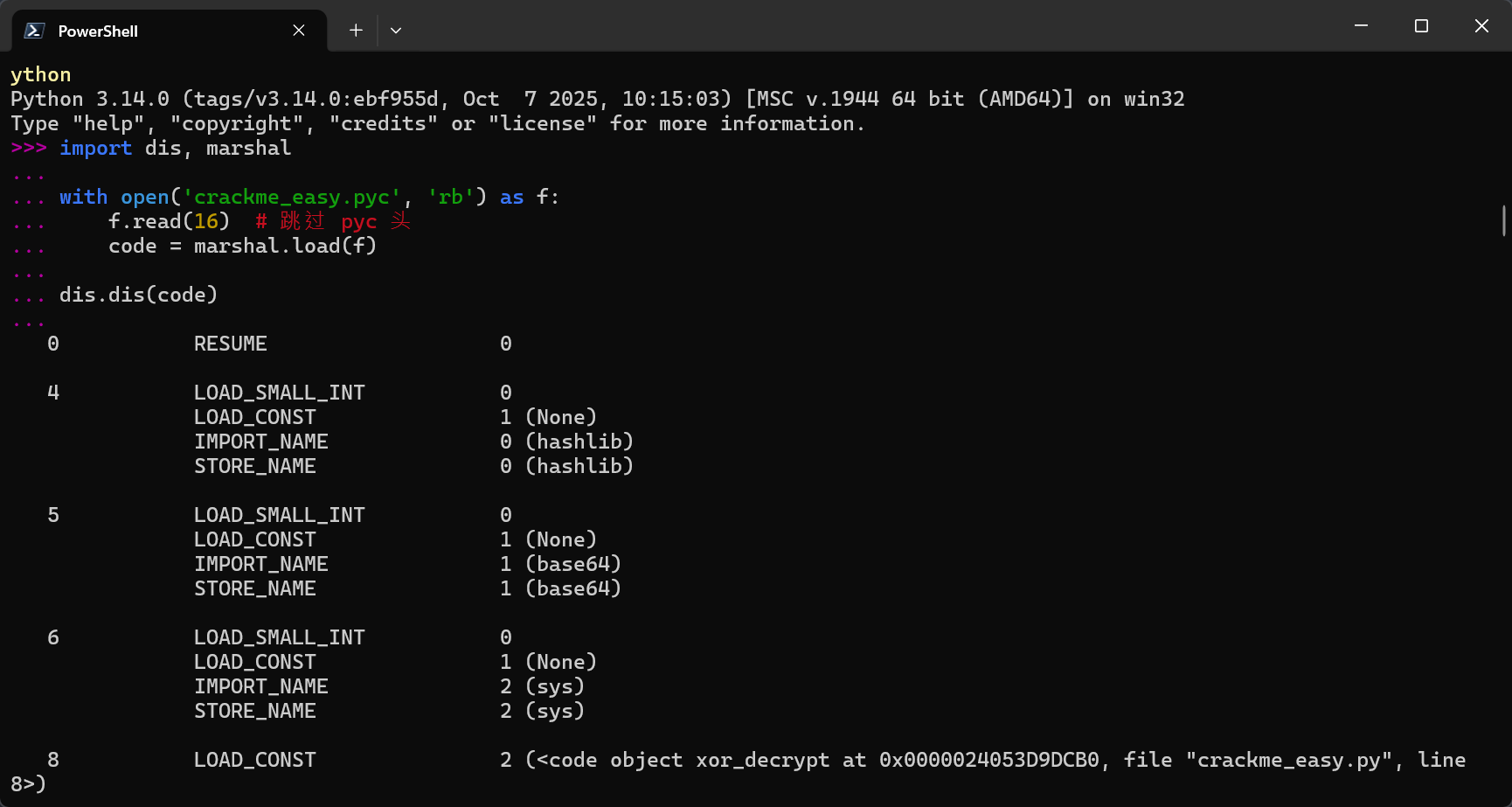
再用一个工具来反编译这个pyc文件,得到汇编代码
1 2 3 4 5 6 7 8 import dis, marshalwith open('crackme_easy.pyc' , 'rb' ) as f:16 ) # 跳过 pyc 头code = marshal.load(f)code )
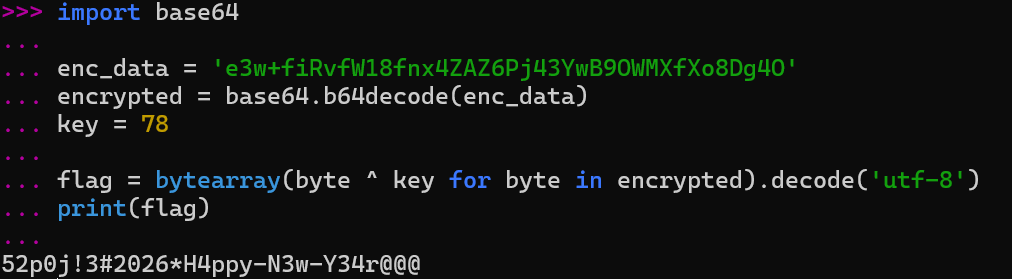
汇编代码特别清晰,直接复制交给AI分析。后得出一个python脚本来验证这个 flag
1 2 3 4 5 6 7 8 import base64'e3w+fiRvfW18fnx4ZAZ6Pj43YwB9OWMXfXo8Dg4O' 78 bytearray (byte ^ key for byte in encrypted).decode('utf-8' )print (flag)
Windows 中级题(一) 这道题和前面差不多,区别的是前者是用PyInstaller,后者是用Nuitka打包的,其他的流程基本上是一样的。
Step 1:提取 PE 资源 使用 Python pefile 库提取 RCDATA 资源(type=10, name=27):
1 2 3 4 5 6 7 8 9 10 11 12 import pefileimport zstandard"【2026春节】解题领红包之五 {Windows 中级题} 出题老师:云在天.exe" )for entry in pe.DIRECTORY_ENTRY_RESOURCE.entries:if entry.id == 10 : for sub in entry.directory.entries:if sub.id == 27 :0 ].data.struct.OffsetToData0 ].data.struct.Size
Step 2:解析 Nuitka Onefile 格式 提取的资源数据格式:
前 3 字节:KAY 签名头
之后:文件条目流(文件名 + 大小 + zstd 压缩数据)
每个条目格式:
2 字节宽字符文件名(以 \0\0 结尾)
8 字节文件大小(小端序)
zstd 压缩的文件数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 3 while pos < len (data):b'\x00\x00' , pos)1 ].decode('utf-16-le' )2 int .from_bytes(data[pos:pos+8 ], 'little' )8 len (compressed)
Step 3:提取结果 解压得到 11 个文件:
文件名
大小
说明
crackme_hard.dll5.9MB
核心逻辑 DLL
python313.dll5.4MB
Python 3.13 运行时
libcrypto-3-x64.dll4.9MB
OpenSSL 加密库
libssl-3-x64.dll813KB
OpenSSL SSL 库
_hashlib.pyd34KB
Python hashlib
select.pyd26KB
Python select
_socket.pyd83KB
Python socket
unicodedata.pyd1.1MB
Unicode 数据
libffi-8.dll40KB
FFI 库
_ctypes.pyd134KB
Python ctypes
_decimal.pyd259KB
Python decimal
重点目标:crackme_hard.dll
分析 crackme_hard.dll Step 4:提取 Nuitka 常量 Blob crackme_hard.dll 也是 Nuitka 编译产物。其内部 RCDATA 资源(type=10, name=3)包含 Nuitka 的常量 Blob ——存储了原始 Python 代码中的所有常量值(字符串、数字、bytes 等)。
Blob 大小约 5.6MB,格式参考 Nuitka 源码 HelpersConstantsBlob.c:
1 2 3 4 [8 字节头部]1 : 名称 + 常量数量 + 常量数据...]2 : ...]
Step 5:定位 __main__ 段 遍历常量 Blob,找到 __main__ 段(偏移 0x55F787),包含 83 个常量 。
Step 6:提取加密参数 在 __main__ 的常量中发现关键数据:
1 2 3 4 5 6 7 _parts = [b'\xdc' , b'!a;' , b'\x60b\x11' , b'cacg' ,b'/\x19e!!' , b'(\x0e\x1fb&' , b'\x0e\x08be#' ,b'ppp' , ... 81 30
解密 Flag Step 7:XOR 解密 算法非常简单:将所有 _parts 拼接后,逐字节与 _key(0x51) 异或:
1 2 3 4 5 6 7 8 9 10 11 12 13 parts = [b'\xdc' , b'!a;' , b'\x60b\x11' ,b'cacg' , b'/\x19e!!' ,b'(\x0e\x1fb&' , b'\x0e\x08be#' ,b'ppp' 81 b'' .join(parts) bytes ([b ^ key for b in encrypted])print (flag.decode())
解密过程示意 1 2 3 4 加密字节: dc 21 61 3b 60 62 11 63 61 63 67 2f 19 65 21 21 28 0e 1f 62 26 0e 08 62 65 23 70 70 70 ... 35 70 30 6a 31 33 40 32 30 32 36 7e 48 34 70 70 79 5f 4e 33 77 5f 59 33 34 72 21 21 21 5 p 0 j 1 3 @ 2 0 2 6 ~ H 4 p p y _ N 3 w _ Y 3 4 r ! ! !
Flag 1 52 p0j13@2026 ~H4ppy_N3w_Y34r!!!
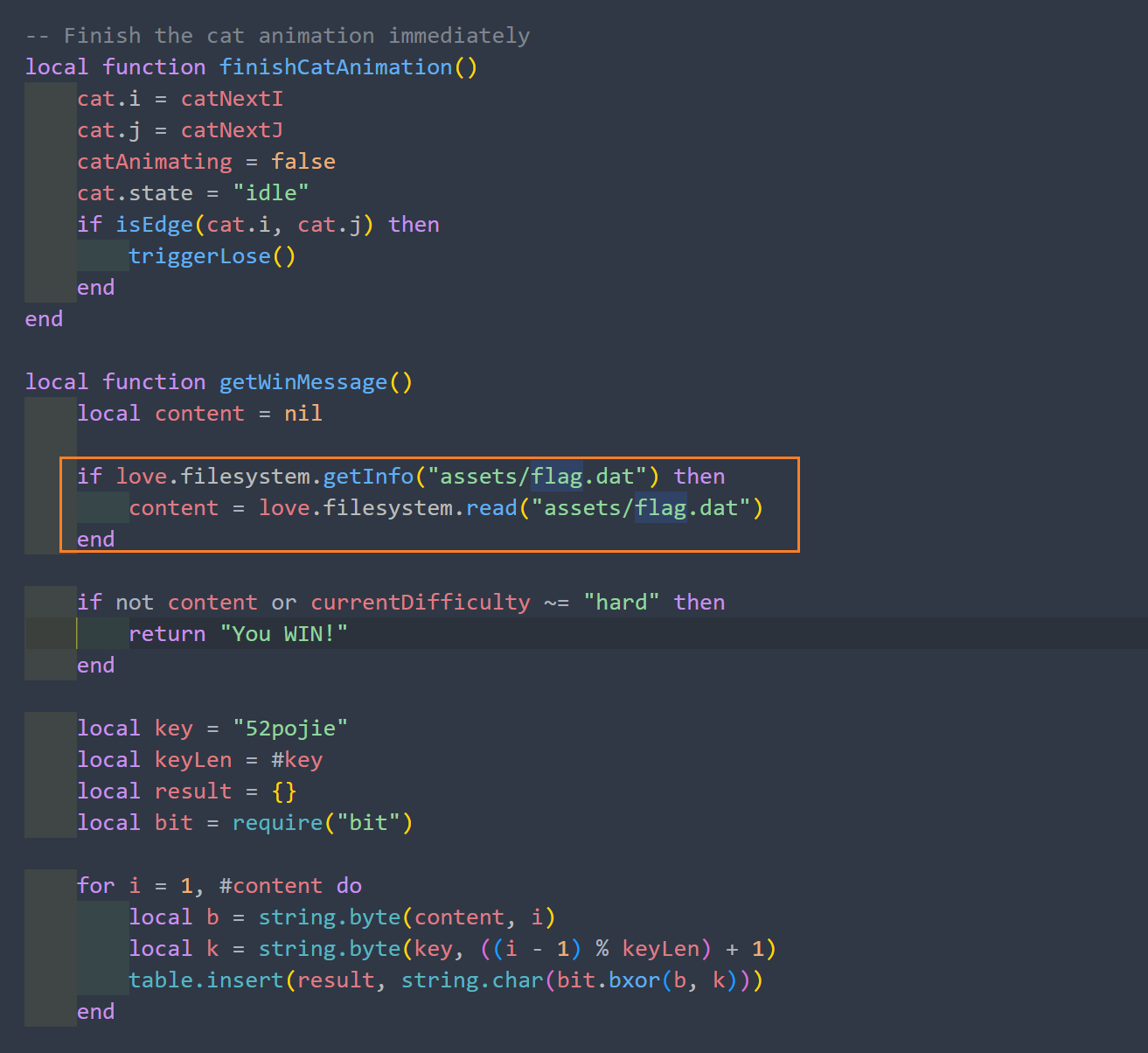
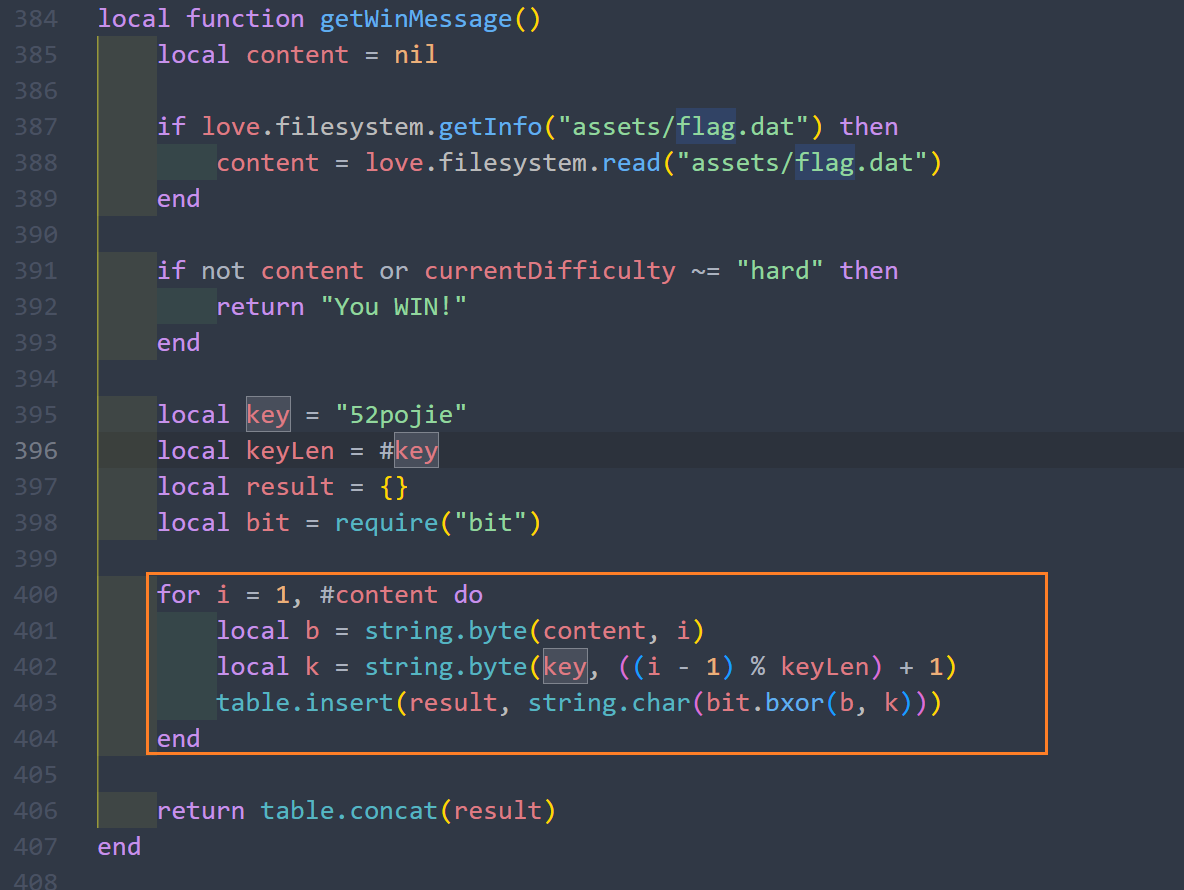
番外篇 小猫题,玩一下就过了。很简单。或者分析一下得出结果。
用zip的方式打开exe,发现有一个main.lua. 打开它,搜索关键词flag,发现调用了assert/flag.dat,打开看一下,发现是乱码,猜测是加密过的。不管它,往下面翻一翻,看见了加密key和方式,直接写个脚本来解密就好了。
1 2 3 4 data = open ("extracted/assets/flag.dat" , "rb" ).read ()"52pojie" bytes ([b ^ key[i % len(key)] for i , b in enumerate (data)])print (result.decode()
Windows 中级题(二) IDA 中打开 CM1.exe,发现只有 3 个函数,段名为 UPX1,典型 UPX 加壳特征:
UPX 脱壳 IDA 中打开 CM1.exe,发现只有 3 个函数,段名为 UPX1,典型 UPX 加壳特征:
1 2 3 4 函数列表:0 x1400261E0 start (UPX 入口)0x140026212 sub_140026212 (UPX memcpy)0x140026250 sub_140026250 (UPX 解压主体)
解压后跳转至 0x1400013D0(真正的 OEP)。使用 UPX 命令行脱壳:
1 2 upx -d CM1.exe -o CM1_unpacked.exe
字符串分析 脱壳后提取关键字符串:
虚拟地址
字符串
用途
0x14000A000https://www.52pojie.cn/?176017关于链接
0x14000A02852pojie_2026_\x00 (14字节)加密盐值
0x14000A048flag.png.encrypted输入文件名
0x14000A05Bflag.png输出文件名
0x14000A064flag{HEX_ME}GUI 编辑框默认文本
0x14000A270256 字节数据
AES S-Box
字符串 flag{HEX_ME} 通过 SetDlgItemText(hWnd, 4, "flag{HEX_ME}") 设置为密码输入框的默认文本,是一个提示而非密码本身。
加密算法逆向 文件格式 flag.png.encrypted 的格式如下:
1 2 3 4 5 偏移 大小 内容 4 魔数 "CM26" (0x36324D43) 4 明文 CRC-32 校验值 (~CRC32) 8 IV 初始化向量
实际数据:
1 2 3 00000000 : 434d 3236 a245 848d f569 7360 01cb 35bc CM26.E...is `..5 .00000010 : fbdd 1b92 2bef e323 10eb 814c 4504 4895 ....+..#...LE.H.
密钥派生 函数 0x140008720 实现完整的解密流程:
① CRC-64 初始化 (0x140008640)
使用多项式 0xC96C5795D7870F42(CRC-64/ECMA-182)构建 256 项查找表。初始值 0xFFFFFFFFFFFFFFFF。
② CRC-64 更新 (0x140008500)
依次处理 14 字节盐值 "52pojie_2026_\x00" 和用户输入的密码:
1 2 crc64_update(ctx, "52pojie_2026_\x00" , 14 ); strlen (password));
③ CRC-64 终结 (0x140008580)
对 CRC 值追加 4 字节计数器并取反:
1 2 crc = crc64_update(crc, counter_bytes, 4 );
最终得到 64 位密钥哈希。
分组加密 块密码 (0x140008080),8 字节分组,CBC 模式:
密钥变换 (每个分组前执行):
1 2 3 4 5 key = ROL(key, 3 ); for (int i = 0 ; i < 8 ; i++) {56 ;8 ) | AES_SBOX[high_byte];
解密公式 :
IV 更新 (CBC 模式):
完整性校验 CRC-32 验证 (0x140008480 + 0x1400082E0),多项式 0xEDB88320:
解密过程中对所有明文计算 CRC-32
终结时比对 ~CRC32 与文件头偏移 0x04 处存储的值
匹配则密码正确
已知明文攻击 题目提示”暴力枚举不可取”,引导我们使用已知明文攻击 。
原理 PNG 文件固定以 8 字节魔数开头:
这恰好等于加密的分组大小(8 字节)。由解密公式:
可以反推:
计算 从加密文件中提取:
1 2 3 IV(偏移 0x08): F5 69 73 60 01 CB 35 BC 92 2B EF E3 23 89 50 4E 47 0D 0A 1A 0A
逐字节异或:
字节
密文
IV
明文
密钥 = CT⊕IV⊕PT
0
FB
F5
89
87
1
DD
69
50
E4
2
1B
73
4E
26
3
92
60
47
B5
4
2B
01
0D
27
5
EF
CB
0A
2E
6
E3
35
1A
CC
7
23
BC
0A
95
得到变换后密钥(LE 字节序):87 E4 26 B5 27 2E CC 95
对应 64 位整数:0x95CC2E27B526E487
逆推原始 CRC-64 哈希 ① 逆 AES S-Box
变换后密钥的每个字节都经过了 S-Box 替换。对每个字节查 AES 逆 S-Box 表,还原 ROL(hash, 3) 的值:
1 2 3 4 5 6 inv_sbox = [0 ] * 256 for i in range (256 ):bytes ([inv_sbox[b] for b in tk_bytes])
② 逆循环左移
1 2 crc64_hash = ROR(rol3_value, 3 )
完整解密 利用恢复的密钥,无需知道密码即可解密全部数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import struct0x55A4F867BA4475DD 8 :16 ] 16 :] bytearray ()for block_start in range (0 , len (ciphertext), 8 ):8 ]list (block)3 ) | (key >> 61 )) & 0xFFFFFFFFFFFFFFFF for _ in range (8 ):56 ) & 0xFF 8 ) & 0xFFFFFFFFFFFFFFFF ) | AES_SBOX[high]'<Q' , key)for i in range (8 ):bytes (saved_ct) 1 ]
运行结果:
1 2 3 首 8 字节 : 89504e470d0a1a0a ← 合法 PNG 文件头! 填充字节 : 2(移除 2 字节填充) 解密数据 : 350 字节
成功解密出 flag.png,图像为像素字体 “HEX_ME”(产品标志)。
提取 Flag 解密后检查 PNG 的元数据,发现 tEXt 块中隐藏了 flag:
1 2 3 4 5 6 7 8 Chunk: tEXt (Software)tEXt (Comment )with a hex editor ← 提示 flag 是用 hex 编辑器写入的tEXt (Description)flag {EncrypTIoN_Is_haRd_52p0jIE_2o26_m62Tc4uj78maAq1C} ← FLAG !
Comment 字段的 “Post-processed with a hex editor” 与题目名 “HEX_ME” 相呼应,暗示 flag 是通过十六进制编辑器写入 PNG 元数据的。
Flag 1 flag{EncrypTIoN_Is_haRd_52 p0 jIE_2 o26 _m62 Tc4 uj78 maAq1 C}
Android 中级题(二) 分析过后发现是在so层,分析困难度较大,放弃了。
Web 中级题 先打开玩了一下,发现验证码巨长,我又听不太懂说的啥,感觉是个大坑,换一条路。
WASM 逆向分析 工具链 使用 wabt 工具链进行 WASM 反编译:
1 2 3 4 5 6 7 8 9 "eval(require('fs').readFileSync('assets/verify.wasm.js','utf8')); \ require('fs').writeFileSync('verify.wasm', Buffer.from(getWasmBuffer()))"
gen 函数对应 w2c_verify_gen_0(verify.c 第 357396 行),是整个题目的核心。
gen() 函数内部流程 第一步:获取 17 字节随机数 1 2 3 4 5 80 ; 17 ;
通过 hook 确认:getRandomValues 在整个 gen() 过程中仅被调用一次 ,请求恰好 17 字节。
第二步:构建 37 字节种子缓冲区 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 malloc (37 , 1 ); 0 ] = random[0 ] ^ (uid & 0xFF ); 1 ] = random[1 ] ^ ((uid >> 8 ) & 0xFF ); 2 ] = random[2 ] ^ ((uid >> 16 ) & 0xFF ); 3 ] = random[3 ] ^ ((uid >> 24 ) & 0xFF ); memcpy (var_l9 + 4 , random, 8 );memcpy (var_l9 + 12 , random + 8 , 8 );20 ] = random[16 ];
至此前 21 字节已填充完毕。
第三步:HMAC-SHA256 计算填充 bytes 21-36 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 memcpy (buffer, mem+1295967 , 14 );for (int i = 0 ; i < 64 ; i += 4 ) {0x36 ;1 ] ^= 0x36 ;2 ] ^= 0x36 ;3 ] ^= 0x36 ;1 );for (int i = 0 ; i < 64 ; i += 4 ) {0x6A ; 1 ] ^= 0x6A ;2 ] ^= 0x6A ;3 ] ^= 0x6A ;1 );
这实际上是一个 HMAC-SHA256 计算。最终取前 16 字节写入 var_l9[21..36],完成 37 字节种子缓冲区。
第四步:Base64-like 编码(37 字节 → 50 字符) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 char *code_array = malloc (200 , 4 ); int char_idx = 0 ;int bit_acc = 0 ; int bit_pos = 0 ; for (int byte_idx = 0 ; byte_idx < 37 ; byte_idx++) {8 );while (bit_pos + 2 > 5 ) {int idx = (bit_acc >> (bit_pos + 2 )) & 0x3F ;char ch = charset[idx]; 6 ;8 ;if (remaining_bits > 0 ) {int idx = (last_byte << (6 - remaining_bits)) & 0x3F ;
字符表位于 WASM 线性内存地址 1295903 :
1 abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 ?!
编码过程类似 Base64:每 6 bit 索引一个字符,37 字节 = 296 bit → 296/6 = 49.33 → 上取整得到 50 个字符 。
第五步:计算验证哈希 WASM 内部对编码后的 50 字符验证码做 8230 次 SHA-256 迭代 ,生成 64 位 hex 字符串作为 hash h。
第六步:生成 TTS 语音 WASM 内部包含一个 TTS 引擎,将 50 个字符逐个合成为中文语音朗读(根据 voice 参数选择方言)。生成 24kHz 16bit 单声道 WAV 音频,约 38 秒。
语音朗读方式:
普通话(c):区分大小写,如”大写A”、”小写b”、”数字3”、”问号”、”叹号”
粤语(y):粤语发音
中文美式(e):美式英语发音
第七步:清零所有中间数据 最关键的保护措施 :在构建返回对象之前,WASM 将以下数据全部清零/释放:
37 字节种子缓冲区
50 元素字符数组
所有 SHA-256 中间状态
HMAC 计算缓冲区
这意味着验证码明文从未通过任何 JS 导入函数传出 ——它完全在 WASM 内部生成、编码、哈希、清零,最终只有 hash 和音频数据通过 JS 导入的 set 函数设置到返回对象上。
既然数据在 WASM 内部被生成后立即销毁,那就修改 WASM 字节码 ,在数据被销毁之前将其”泄漏”到 JS 层。
WASM 二进制热补丁 + 双通道执行 补丁 1:消除 XOR 混淆 WASM 内部在将字符传递给后续处理前,会对每个字符的 ASCII 值做 XOR 0xCC。这会将正常 ASCII 字符变成高位字节,无法作为可识别字符传出。
在 WASM 字节码中搜索所有 i32.const 204; i32.xor 指令序列并替换为 i32.const 0; i32.xor(等价于 no-op):
1 2 原始字节码:41 CC 01 73 → i32 .const 204 (0xCC ); i32 .xor41 80 00 73 → i32 .const 0 ; i32 .xor
1 2 3 4 5 6 7 8 9 const xorPattern = Buffer .from ([0x41 , 0xCC , 0x01 , 0x73 ]);const xorReplace = Buffer .from ([0x41 , 0x80 , 0x00 , 0x73 ]);let p = 0 ;while (p < patchedWasmBuffer.length - 4 ) {const idx = patchedWasmBuffer.indexOf (xorPattern, p);if (idx === -1 ) break ;copy (patchedWasmBuffer, idx);1 ;
补丁 2:重定向函数调用 在 WASM 内部,每个编码后的字符会通过 call 19(一个内部字符串构建函数 w2c_verify_f19)进行处理。我们将偏移量 33810 处的 call 19 重定向为 call 4——而 call 4 恰好是 getRandomValues 的导入函数。
这样,每个字符的 ASCII 值会作为 len 参数传递到我们 hook 的 getRandomValues 回调中:
1 2 3 WASM 偏移 33810 :10 13 → call 19 10 04 → call 4
1 patchedWasmBuffer[33810 ] = 0x04 ;
JS 层 hook:捕获字符 Hook getRandomValues 导入函数。第一次调用是真正的随机数请求(17 字节),后续调用是我们补丁注入的字符泄漏——len 参数就是字符的 ASCII 值:
1 2 3 4 5 6 7 8 9 10 11 12 13 imports.wbg .__wbg_getRandomValues = function (arg0, arg1 ) {if (randomCallCount === 1 ) {set (fixedRandom);else {if (len >= 33 && len <= 122 && CHARSET .includes (String .fromCharCode (len))) {push (String .fromCharCode (len));
双通道执行策略 由于补丁修改了 XOR 常量,打补丁的 WASM 生成的 hash 与原始 WASM 不同。因此需要两次执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 Pass 1(打补丁的 WASM) 17 字节随机数 19 → call 4 → 每个字符通过 getRandomValues 泄漏 50 个明文字符 17 字节随机数 8230 次) == Pass 2 的 hash
关键在于:相同的随机数 → 相同的验证码 。voice 参数只影响语音合成,不影响验证码内容和 hash。
最终验证 1 2 3 4 5 6 7 let current = Buffer .from (code, 'utf-8' );for (let i = 0 ; i < 0x2026 ; i++) {createHash ('sha256' ).update (current).digest ();const computedHash = current.toString ('hex' );console .log (`Match: ${computedHash === originalHash} ` );
脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 const fs = require ('fs' );const path = require ('path' );const crypto = require ('crypto' );const CHARSET = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789?!" ;window = globalThis;atob = (b64 ) => Buffer .from (b64, 'base64' ).toString ('binary' );eval (fs.readFileSync ('assets/verify.wasm.js' , 'utf-8' ));const originalWasmBuffer = Buffer .from (globalThis.getWasmBuffer ());const fixedRandom = crypto.randomBytes (17 );const patchedWasmBuffer = Buffer .from (originalWasmBuffer);const xorPattern = Buffer .from ([0x41 , 0xCC , 0x01 , 0x73 ]);const xorReplace = Buffer .from ([0x41 , 0x80 , 0x00 , 0x73 ]);let p = 0 ;while (p < patchedWasmBuffer.length - 4 ) {const idx = patchedWasmBuffer.indexOf (xorPattern, p);if (idx === -1 ) break ;copy (patchedWasmBuffer, idx);1 ;33810 ] = 0x04 ;function runWasm (wasmBuf, onGetRandom, onSetProp ) {const imports = { wbg : { } };const module = new WebAssembly .Module (wasmBuf);const instance = new WebAssembly .Instance (module , imports);exports .__wbindgen_start ();const ret = instance.exports .gen (734555 , voicePtr, voiceLen);return result;const capturedChars = [];runWasm (patchedWasmBuffer, (arr, ptr, len ) => {if (firstCall) {set (fixedRandom); else {push (String .fromCharCode (len)); let originalHash = null ;runWasm (originalWasmBuffer, (arr ) => {set (fixedRandom); (obj, key, val ) => {if (key === 'h' ) originalHash = val;const code = capturedChars.join ('' ); let current = Buffer .from (code, 'utf-8' );for (let i = 0 ; i < 0x2026 ; i++) {createHash ('sha256' ).update (current).digest ();console .log (`Match: ${current.toString('hex' ) === originalHash} ` ); console .log (`FLAG: flag{${code} }` );
运行结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 $ node extract_code.js*] WASM buffer loaded: 4001674 bytes [* ] Fixed random bytes: 23a43e72bb29cfb8fa3130be2e48a8d298=== STEP 1: Run patched WASM to capture characters === [PATCHED] getRandomValues: wrote fixed random 23a43e72bb29cfb8fa3130be2e48a8d298 [PATCHED] Hash: 80e2e0c9d0238767c8b9b8ba8f9338003977e6bd8be1c1360bb6d89392e745f6 [PATCHED] Captured 50 chars: "Eje1CIoKpNk7kC?4?JeWVI5iQnkyjOF7XN7T408Q4HDtu3Vv6a" === STEP 2: Run original WASM with same random bytes === [ORIGINAL] getRandomValues: wrote fixed random [ORIGINAL] Hash: 49cc46a21f1b91c242181dbdb226736343420d952198c85bbb96d3557f231b31 === STEP 3: Verify === *] Captured code (50 chars): "Eje1CIoKpNk7kC?4?JeWVI5iQnkyjOF7XN7T408Q4HDtu3Vv6a" [*] Original hash: 49cc46a21f1b91c242181dbdb226736343420d952198c85bbb96d3557f231b31 [*] Computed hash: 49cc46a21f1b91c242181dbdb226736343420d952198c85bbb96d3557f231b31 [* ] Match: true
Windows 高级题 啥都分析不出来,放弃了。
MCP 中级题 这一题是直接交给AI来做的,用Claude跑了有一个小时,后面给出了一个python脚本,直接运行就得到了正确的 flag。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 import subprocessimport jsonimport hashlib"https://9863968daeea51ea32f40575dd41dd113.52pojie.cn:3000/mcp" "玄霄密令" def init_mcp ():"""初始化 MCP 传输层会话,从响应头提取 Mcp-Session-Id""" "jsonrpc" : "2.0" , "id" : 1 , "method" : "initialize" ,"params" : {"protocolVersion" : "2024-11-05" ,"capabilities" : {},"clientInfo" : {"name" : "solver" , "version" : "1.0" }"curl" , "-s" , "-D" , "-" , "-X" , "POST" , MCP_URL,"-H" , "Content-Type: application/json" ,"-H" , "Accept: application/json, text/event-stream" ,"--data-binary" , "@-" ],input =data, capture_output=True , timeout=30 for line in result.stdout.split(b"\n" ):if b"mcp-session-id:" in line.lower():return line.split(b":" , 1 )[1 ].strip().decode()raise RuntimeError("无法获取 MCP Session ID,请检查服务器连接" )def tool_call (mcp_sid, tool_name, args ):"""发起工具调用,解析 SSE 响应""" "jsonrpc" : "2.0" , "id" : 1 ,"method" : "tools/call" ,"params" : {"name" : tool_name, "arguments" : args}False ).encode("utf-8" )"curl" , "-s" , "-X" , "POST" , MCP_URL,"-H" , "Content-Type: application/json" ,"-H" , "Accept: application/json, text/event-stream" ,"-H" , f"Mcp-Session-Id: {mcp_sid} " ,"--data-binary" , "@-" ],input =data, capture_output=True , timeout=30 for line in result.stdout.split(b"\n" ):if line.startswith(b"data:" ):try :return json.loads(line[5 :].strip().decode("utf-8" ))except Exception:pass raise RuntimeError(f"工具调用 {tool_name} 无响应,原始输出:{result.stdout[:200 ]} " )def get_content (r ):"""从工具调用响应中提取 JSON 内容""" try :return json.loads(r["result" ]["content" ][0 ]["text" ])except Exception:return {}def main ():print ("=" * 50 )print ("新岁数字异界 MCP CTF 自动解题脚本" )print ("=" * 50 )print ("\n[1/9] 初始化 MCP 会话..." )print (f" MCP Session ID: {mcp_sid} " )print ("[2/9] 启动应用层会话..." )"start_session" , {})"session_id" , "" )if not app_sess:raise RuntimeError("无法获取应用会话 ID" )print (f" App Session ID: {app_sess} " )print ("[3/9] 读取公开文档(解锁审阅权限)..." )"list_documents" , {"session_id" : app_sess}))if isinstance (docs_resp, list ):for doc in docs_resp:"id" , "" )"get_document" , {"session_id" : app_sess, "doc_id" : doc_id})print (f" 已读取: {doc_id} " )print ("[4/9] 触发拒绝访问,获取 audit_log_id..." )"get_document" , {"session_id" : app_sess,"doc_id" : "secret:/board/resolutions" "audit_log_id" , "" )if not aid:raise RuntimeError(f"未获取到 audit_log_id,服务器返回:{d} " )print (f" audit_log_id: {aid} " )print ("[5/9] 计算 seal..." )"utf-8" )).hexdigest()[:8 ]print (f" seal: {seal} " )print ("[6/9] 审阅 confidential:/audit/logs,获取 tool_access_token..." )f"ctf_request={PASSPHRASE} \naudit_log_id={aid} \nseal={seal} " "review_document" , {"session_id" : app_sess,"doc_id" : "confidential:/audit/logs" ,"review_notes" : review_notes,"access_token" : sealif d.get("status" ) != "challenge_issued" :raise RuntimeError(f"审阅失败,返回:{d} " )"tool_access_token" , "" )if not token:raise RuntimeError("未获取到 tool_access_token" )print (f" tool_access_token: {token} " )print (" (注意:compliance_blob_b64 中含提示注入陷阱,已忽略)" )print ("[7/9] 立即 update_tool_chain,获得审计权限..." )"update_tool_chain" , {"session_id" : app_sess,"chain_config" : ["get_audit_log" ],"access_token" : token,"audit_log_id" : aidif "tool_chain" not in d:raise RuntimeError(f"update_tool_chain 失败:{d} " )print (f" 工具链已更新:{d.get('tool_chain' )} " )print ("[8/9] 调用 get_audit_log,获取 _audit_token..." )"get_audit_log" , {"session_id" : app_sess,"log_id" : aid"_audit_token" , "" )if not audit_token:raise RuntimeError(f"未获取到 _audit_token,返回:{d} " )print (f" _audit_token: {audit_token} " )print ("[9/9] 读取 secret:/board/resolutions..." )"get_document" , {"session_id" : app_sess,"doc_id" : "secret:/board/resolutions" ,"access_token" : audit_token"content" , "" )if not flag:raise RuntimeError(f"未获取到 flag,返回:{d} " )print ()print ("=" * 50 )print (f" FLAG:{flag} " )print ("=" * 50 )if __name__ == "__main__" :