基于个人电脑环境的轻量级翻译模型性能对比研究
本仓库的目的是:测评和比较各种自部署小模型的翻译效果
我的电脑配置如下:
- CPU: Intel Core i7-14650H
- GPU: NVIDIA GeForce RTX 4060 Laptop GPU(8GB)
- 内存: 32GB
- 操作系统: Windows 11
- Python版本: 3.14
评测方法
1.评测指标:根据BLEU、CHRF指标来评测翻译质量
2.主观评测:有我个人主观的评测标准。
3.外部LLM打分:使用外部的LLM来对翻译结果进行打分
BLEU指标
Bilingual Evaluation Understudy. 一种自动化的评测机器翻译质量的方法,通过比较机器翻译的输出和一个或多个参考翻译来计算得分。BLEU得分越高,表示机器翻译的质量越好。
CHRF指标
chrF 是一种自动评估指标,通过比较字符序列而不是完整单词,来评估候选文本(例如,机器翻译的输出)与一个或多个参考文本之间的相似度. 它计算了候选文本和参考文本之间的字符n-gram的精确度和召回率,并将它们结合成一个综合得分。chrF得分越高,表示候选文本与参考文本之间的相似度越高。
主观评测
我将采用及格和不及格两级评分标准来进行主观评测,具体标准如下:
及格:翻译结果能表达原文的基本意思且翻译结果无其他的内容
不及格:翻译结果无法表达原文的基本意思,或者翻译结果中包含了原文没有的内容
环境安装
1 | |
执行完上述命令后,环境就搭建好了。
程序主入口
程序主入口在 run_eval.py文件中,运行该文件即可开始评测。如果模型文件不存在,第一次运行的时候会自动下载模型。默认运行的是全部模型的评测,如果只想评测某个模型,可以使用以下命令:
1 | |
另外还有其他的命令行参数可以使用,具体可以使用以下命令来查看:
1 | |
如何添加新的模型?
在 config/models.yaml文件中添加新的模型配置,然后在 translators文件夹中实现对应的翻译器类。完成后就可以在评测中使用新的模型了。
对应的翻译类可以继承 BaseTranslator类,并实现其中的两个方法(理论上来讲只需要实现两个,并且都是大同小异)。具体可以参考 translators/smolLM3.py文件中的 SmolLMTranslator类的实现。
实现完成后可以使用以下命令来运行评测:
1 | |
其中 MODEL_NAME是你想要评测的模型名称,必须与 config/models.yaml中的配置一致。
另外,config/models.yaml 中的model_name 必须要和HuggingFace上模型的名称一致,否则程序会无法下载模型文件。
测试数据
测试数据保存在 data文件夹中,格式为JSON。
1 | |
以上为一个测试数据的示例,包含了源语言文本、参考翻译文本、源语言和目标语言的信息。
src_lang和tgt_lang的值可以在 utils/lang_codes.py文件中找到
外部LLM打分
如果启用了外部LLM打分功能,需要格外的配置API_KEY。配置示例请看 .env.example文件。
也可以使用中转站的来进行API调用,修改 config/scoring.yaml文件中的配置即可。
1 | |
以上为配置示例,启用某个模型的打分功能需要将对应的 enabled字段设置为 true,并且配置好API_KEY。
评测结果
评测的结果会保存在 results文件夹中,每个模型的评测结果会保存在一个单独的文件中。
评测结果的格式为JSON,包含了每个测试数据的源文本、参考翻译、模型翻译结果、BLEU得分、CHRF得分以及外部LLM打分(如果启用了的话)。
1 | |
其中 source为源文本,reference为参考翻译(Google translate),translation为模型翻译结果,src_lang和 tgt_lang分别为源语言和目标语言,bleu和 chrf分别为BLEU得分和CHRF得分,time_seconds为模型翻译所花费的时间(单位为秒), avg_llm_score为外部LLM打分的平均分,满分十分。
介绍完整个评测流程和结果的格式后,接下来我们就可以开始正式的评测了。
本次采用的测试数据为L站的社区规则和站长的帖子中的一些内容。
评测结果分析
评测结果保存在 results文件夹中,每个模型的评测结果会保存在一个单独的文件中。在本次测试中一共使用了五个模型,分别是nllb-200-distilled-600M、m2m100-418M、qwen2.5-3b,SmolLM3-3B和HY-MT1.5-1.8B。测试数据集在 data文件夹中,包含了9条测试数据。
在程序运行完后,可以看到在 results文件夹中分别生成了五个不同的评测结果文件和一个 comparison.json文件。每个评测结果文件中包含了对应模型的翻译结果和评测指标,而 comparison.json文件则包含了所有模型的翻译结果和评测指标,方便进行比较分析。
在本机上运行测试程序的大概时间为20分钟左右。
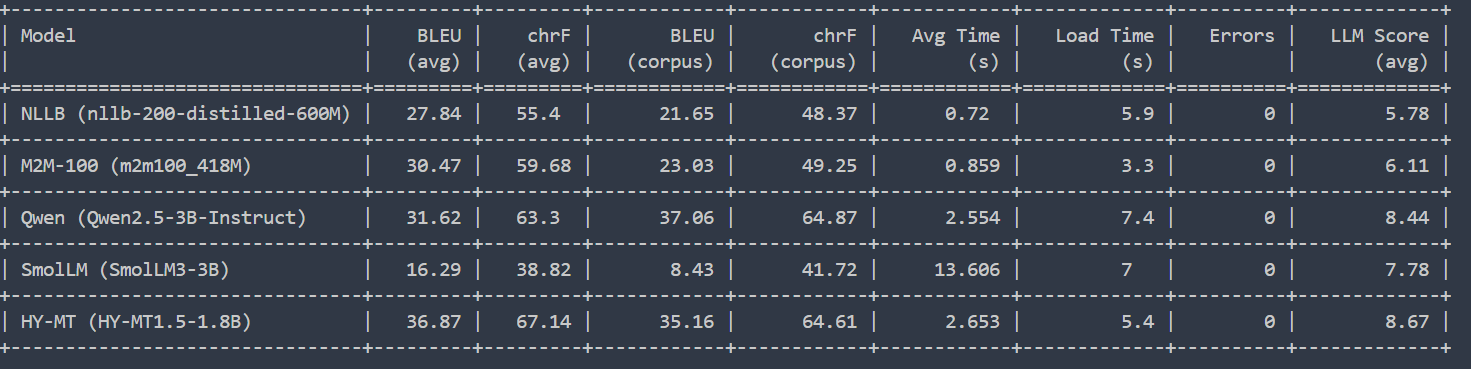
上图为五个模型的比分。
其中HY-MT1.5-1.8B的表现最好,分数是最好的,用的时间也相对来说较短,我的的评价是夯爆了,用Deepseek打分也是最高分(用的是自己的API_KEY, 其他的LLM我没有Key,只能测试一个了)
- NLLB (nllb-200-distilled-600M)
- 质量: BLEU和chrF分数都处于中等偏下的水平(BLEU avg: 27.84, BLEU corpus: 21.65, chrF avg: 55.4, chrF corpus: 48.37),LLM Score也相对较低(5.78)。
- 效率: 处理速度非常快(Avg Time: 0.72秒),加载时间也相对较快(5.9秒)。
进入到详细的评测结果分析中,Deepseek打出了6分(其中一个测试数据)。虽然DeepSeek给出了6分,但是我能读懂它的翻译结果,基本上能看懂。我也不是英语专业的,给一个及格。
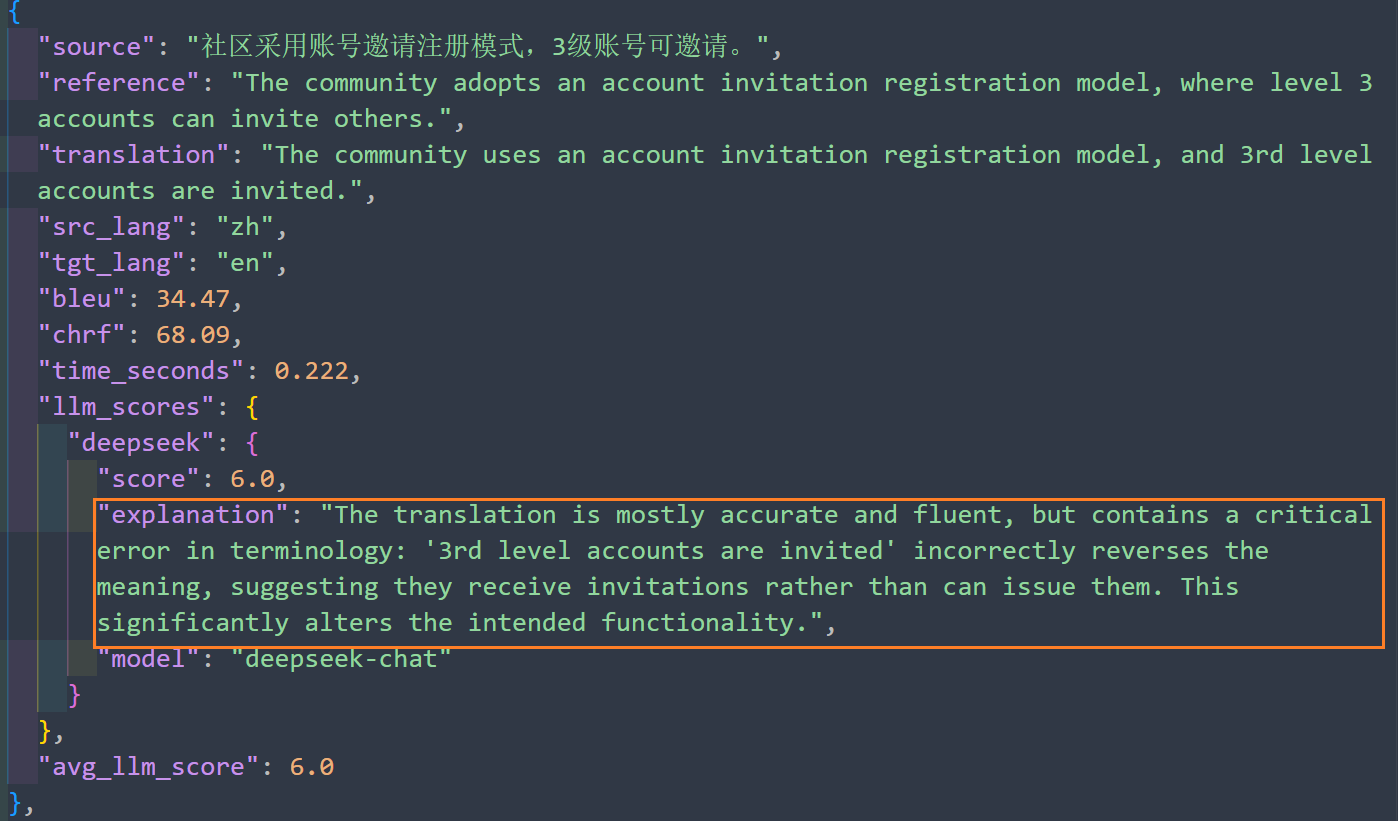
另外在长文的情况下,Deepseek只给这个模型打了三分
- M2M-100 (m2m100_418M)
- 质量: 质量比NLLB略好一些(BLEU avg: 30.47, BLEU corpus: 23.03, chrF avg: 59.68, chrF corpus: 49.25),LLM Score也稍高(6.11)。
- 效率: 处理速度同样非常快(Avg Time: 0.859秒),加载时间是所有模型中最快的(3.3秒)。
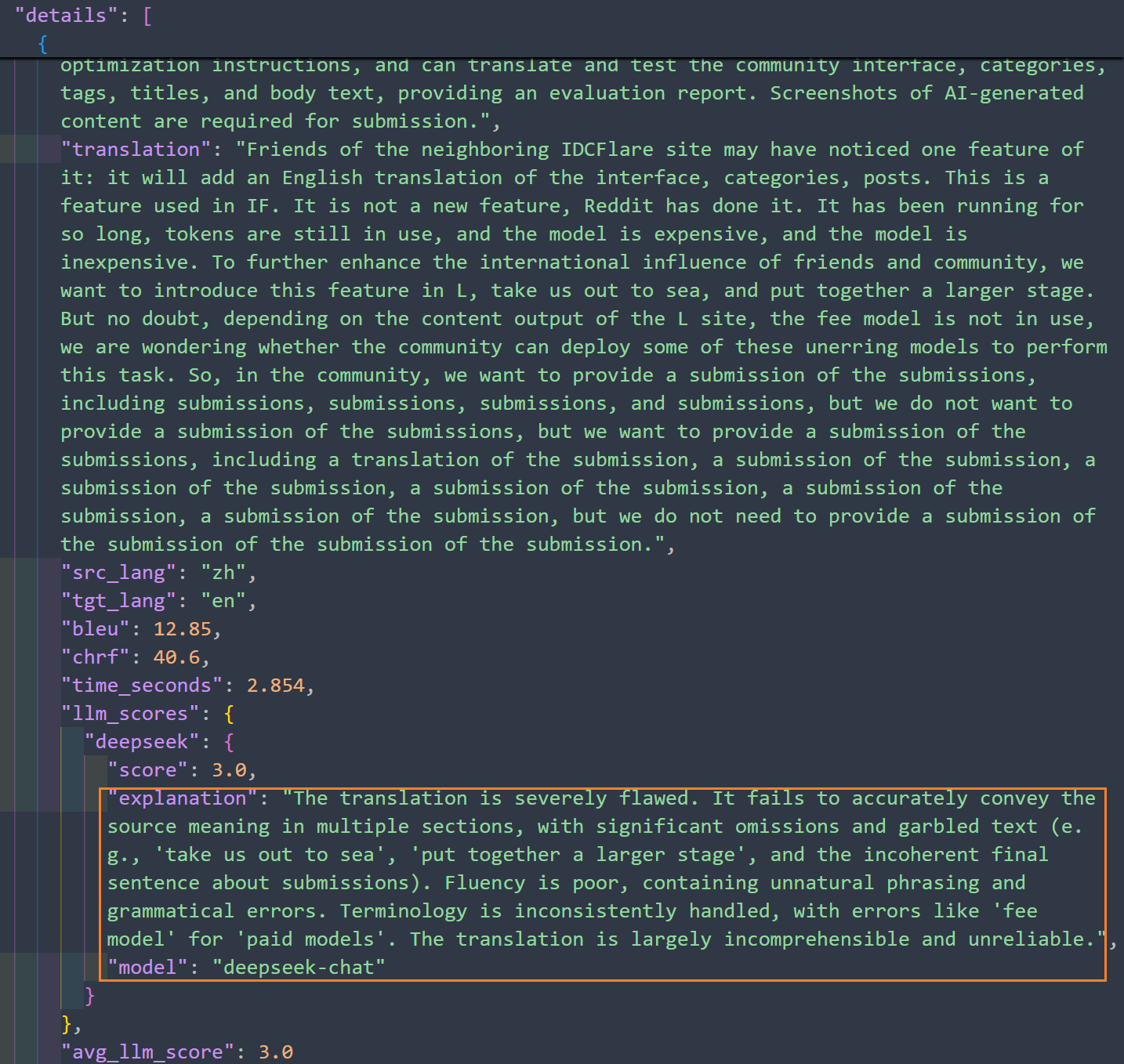
一样的,咱们看Deepseek的打分,在长文的情况下,翻译有一些小错误
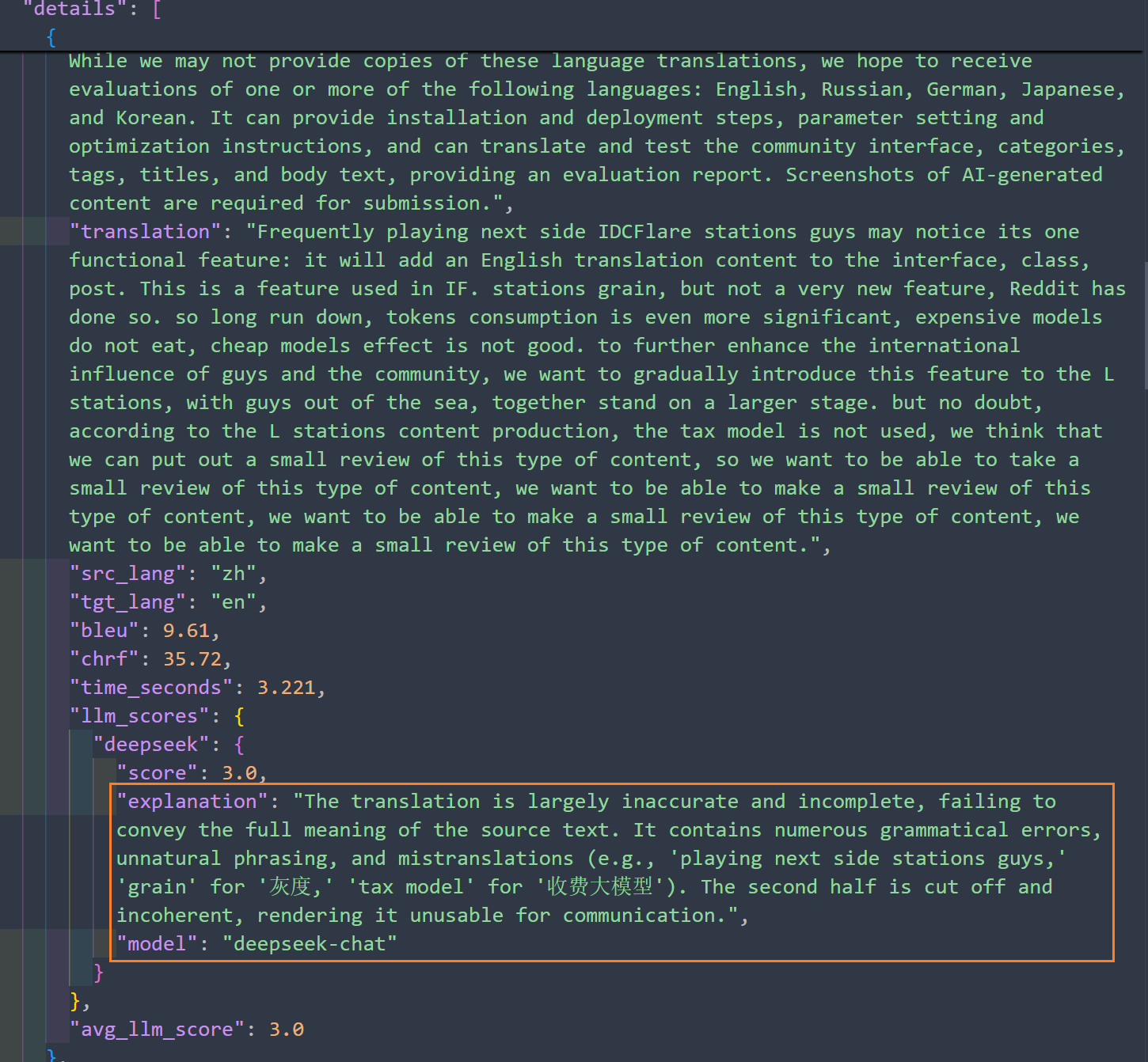
在短文本的情况下,翻译结果Deepseek打的分数也不是很高。我给一个及格。

- Qwen (Qwen2.5-3B-Instruct)
- 质量: 质量表现非常出色,BLEU corpus(37.06)和chrF corpus(64.87)显著高于NLLB和M2M-100。LLM Score也达到了很高的8.44分。
- 效率: 处理时间(Avg Time: 2.554秒)和加载时间(7.4秒)都相对较长。
在长文本和短文本的情况下,这个模型的翻译结果都还不错,Deepseek的打分也比较高,基本上都是8分以上,我个人的打分也是及格的。
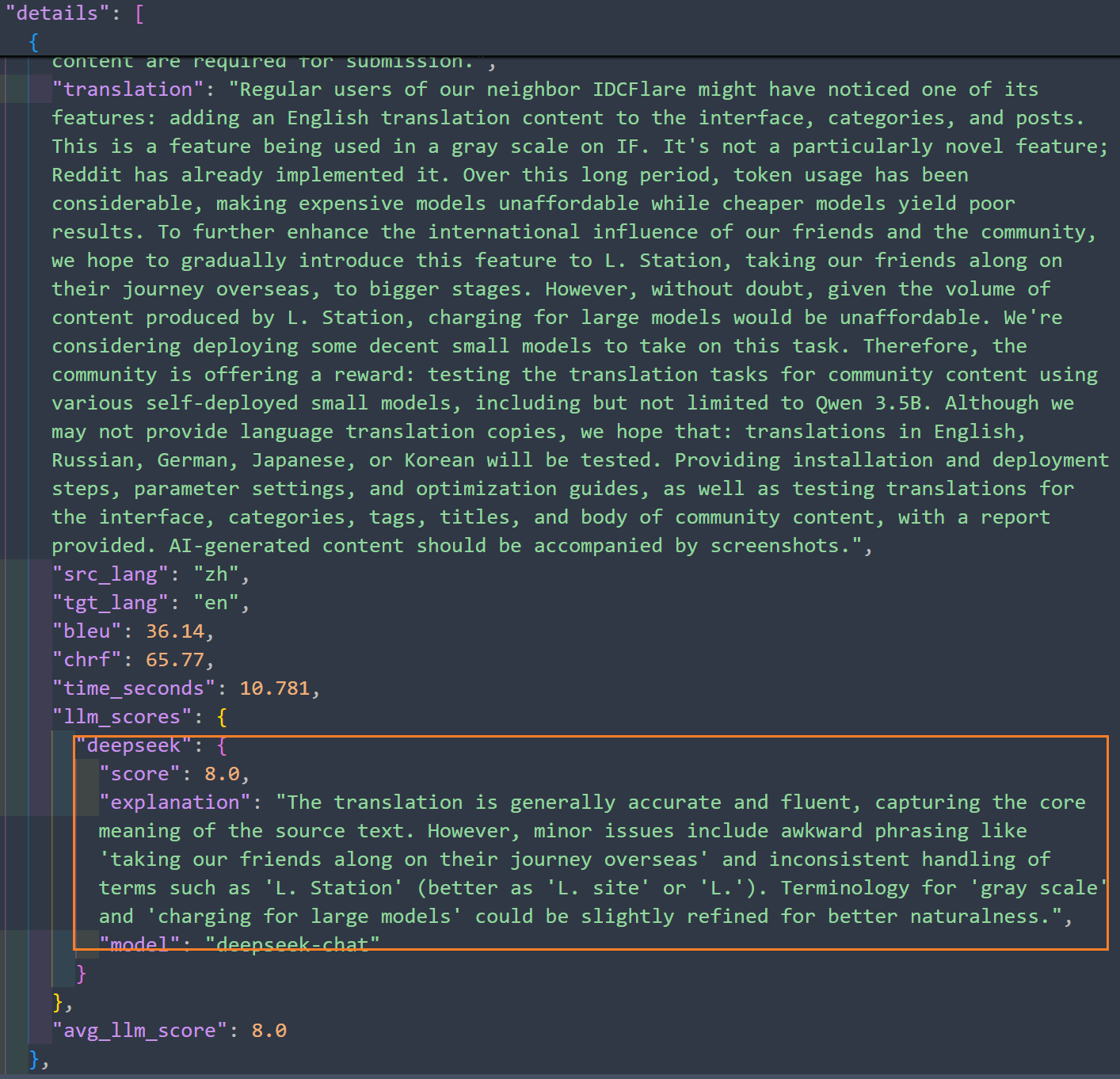
- SmolLM (SmolLM3-3B)
- 质量: 这个模型的各项质量指标都非常低(BLEU avg: 16.29, chrF avg: 38.82, BLEU corpus: 8.43, chrF corpus: 41.72),是所有模型中最差的。然而,它的LLM Score(7.78)却相对较高,这可能意味着尽管在传统指标上表现不佳,但在某些主观评估上,LLM认为其生成的内容有一定可用性,或者在特定评估维度上有所突出(但从BLEU和chrF来看,其直接翻译的准确性存疑)。
- 效率: 处理时间(13.606秒)和加载时间(7秒)都非常长,是所有模型中最慢的。
我给出评价是拉完了,翻译的结果还有原文和思考过程。拉完了,虽然Deepseek给了分数都是六分往上。也有可能是我的用法不对,此处交给其他有经验的同学了。
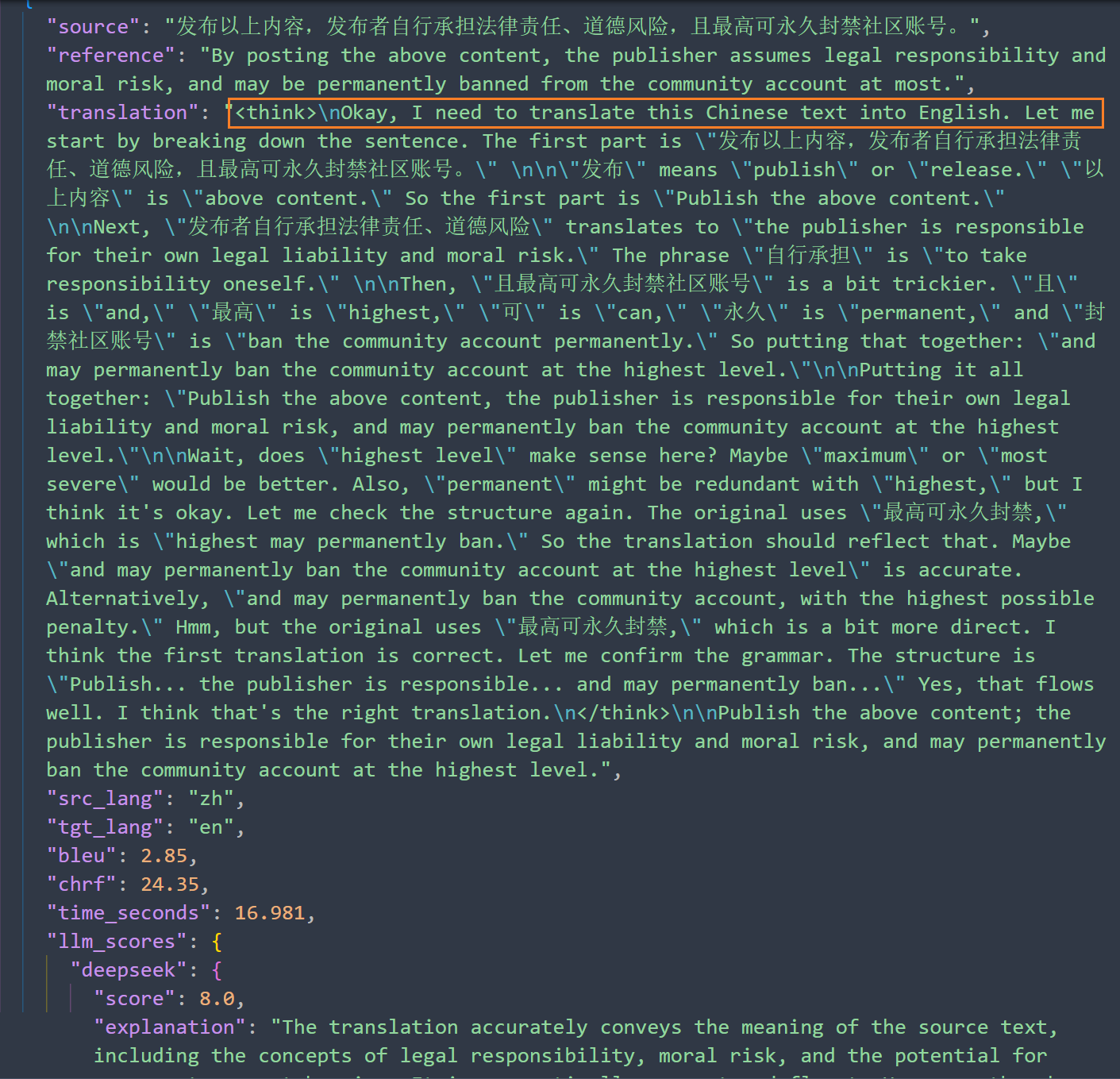
- HY-MT (HY-MT1.5-1.8B)
- 质量: 翻译质量是所有模型中最好的。它的BLEU avg: 36.87,chrF avg: 67.14 是最高分;BLEU corpus: 35.16,chrF corpus: 64.61 也非常高。LLM Score也达到了最高的8.67分。
- 效率: 处理时间(Avg Time: 2.653秒)和加载时间(5.4秒)都处于中等水平,比Qwen稍快。
输出的结果比上一个好,没有思考过程,翻译结果也都是是准确的。 Deepseek的打分也比较高,基本上都是8分以上。
总结
HY-MT (HY-MT1.5-1.8B) 毫无疑问是是本次测试翻译质量最好的模型,各项指标全面领先。
Qwen (Qwen2.5-3B-Instruct) 提供了非常高的翻译质量,但速度相对较慢。如果能接受略长的等待时间,这也是一个优秀的选择
最快速度 (Fastest Speed): NLLB (nllb-200-distilled-600M) 提供最快的处理速度,但质量相对较低
最差表现 (Worst Performance): SmolLM (SmolLM3-3B) 在所有方面都表现最差,不推荐使用(拉完了)
另外模型还能够翻译其他语言,在本文中,只对英文和中文的翻译效果进行了评测,其他语言的翻译效果还需要进一步测试和分析。
本文的测试结果仅供参考,评测结果可能会受到测试数据、评测指标和外部LLM打分的影响。建议在实际应用中根据具体需求选择合适的模型,并进行充分的测试和验证。
如果还需测试其他模型,请根据上方的说明添加新的模型配置和翻译器类,然后运行评测程序进行测试。
如果程序有任何问题或者有任何建议,欢迎提交issue或者pull request,我会尽快回复和处理。